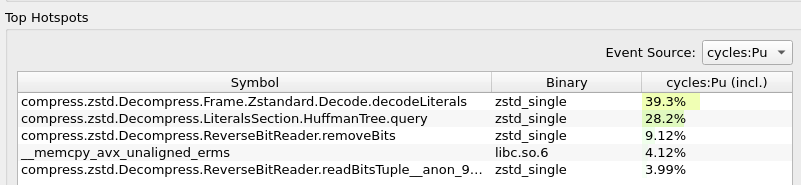
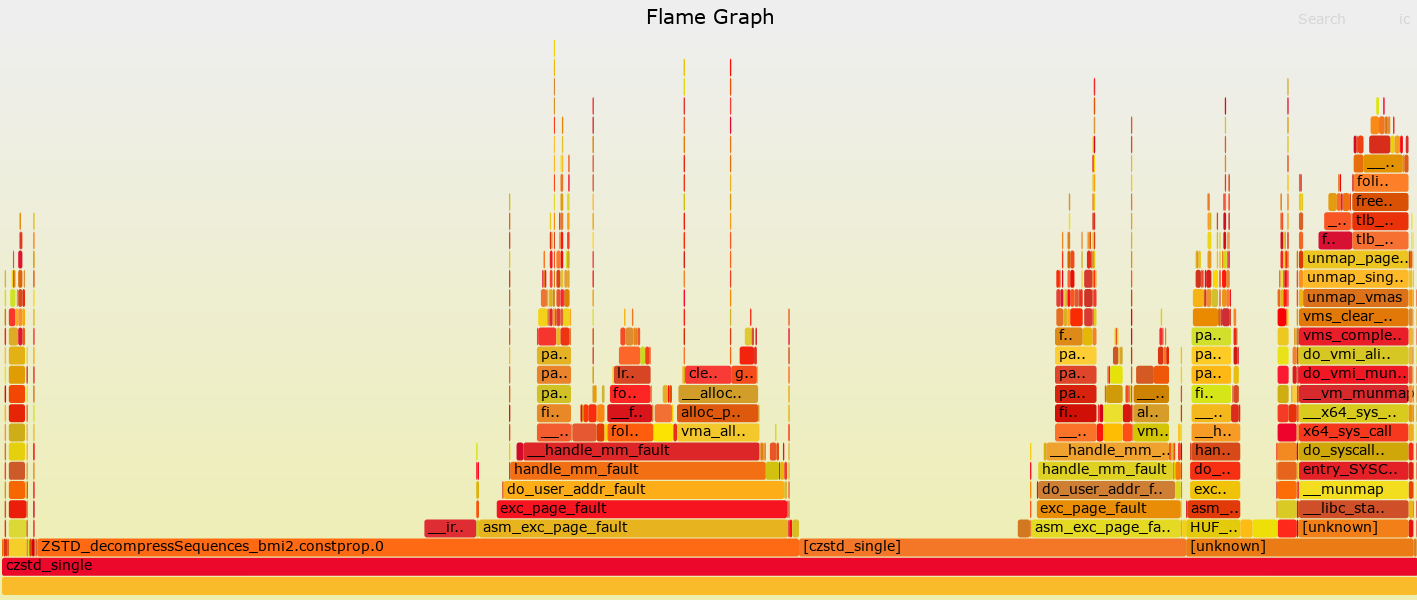
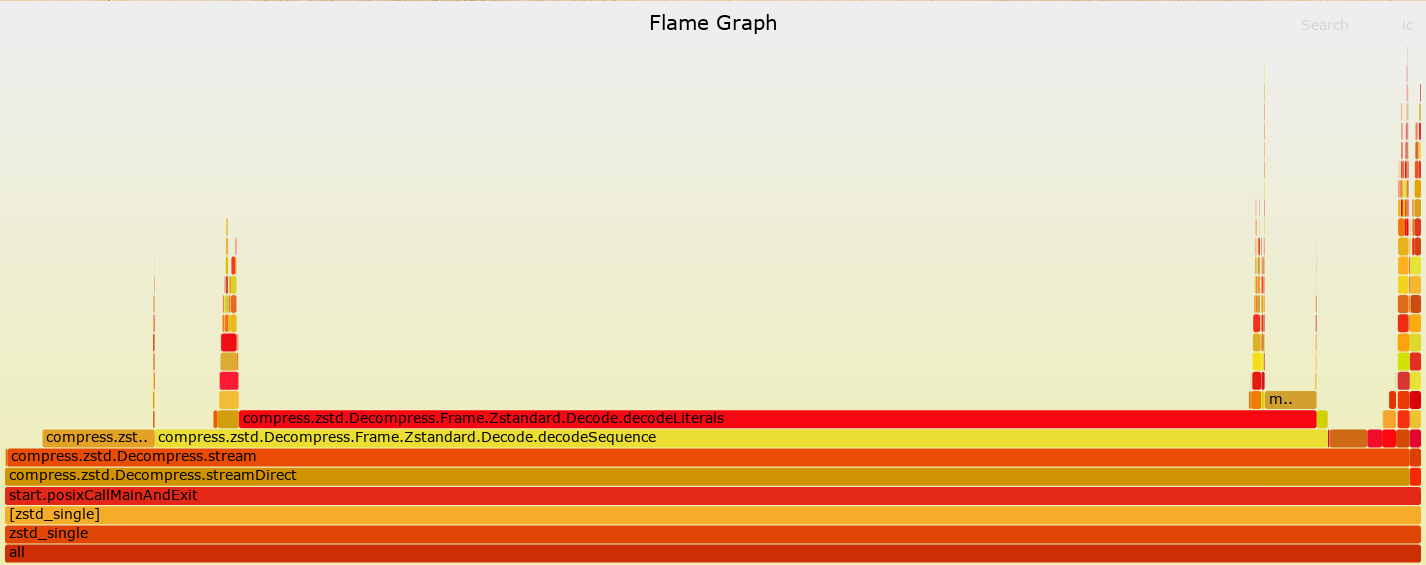
Hey! I’m currently working on Zstandard decompression performance issue, whose goal is to benchmark the Zig std Zstd decompression implementation, compare it with the reference C implementation, and possibly propose improvements.
I’ve already done some work on this, but I’m not confident that all the decisions I made along the way were justified and the results I got were valid. So, I’d like to discuss a few things with the community here before reopening the issue on Codeberg. I’d be glad to hear any opinions or suggestions about the issue in general or about the results I present below.
First of all, the results I currently have:
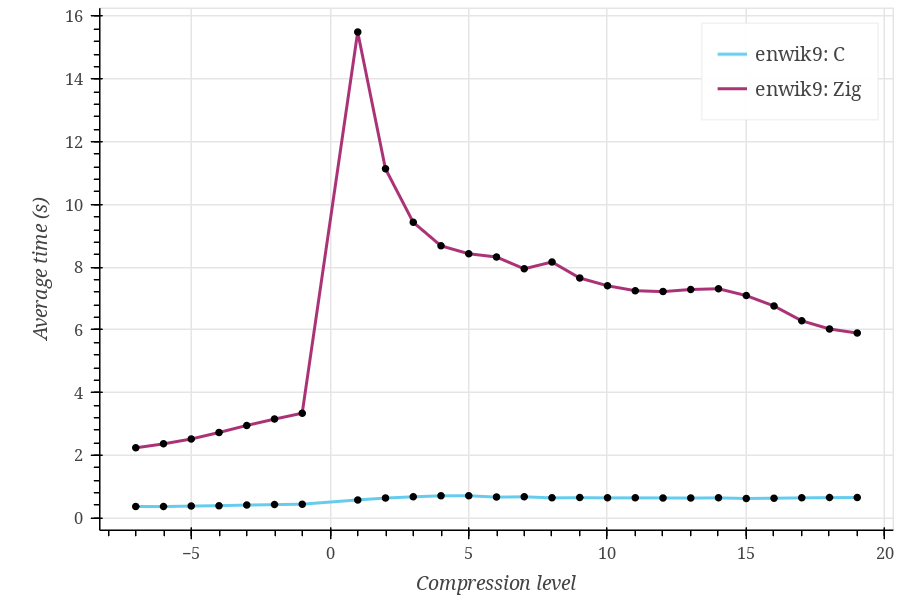
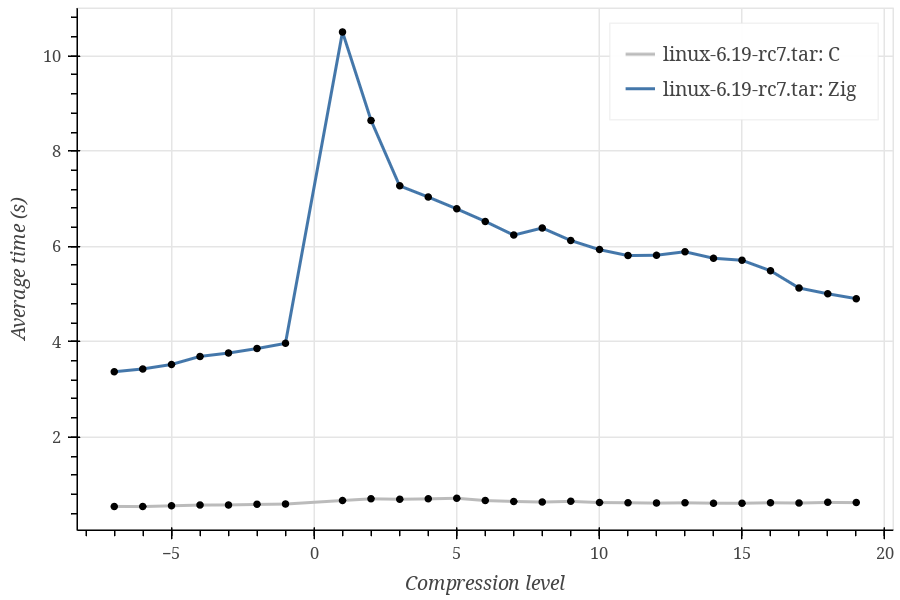
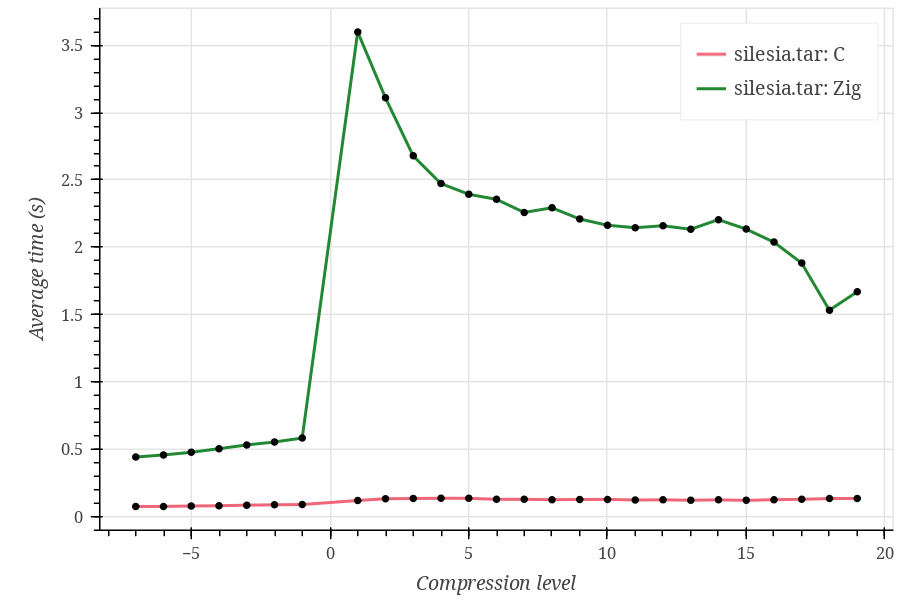
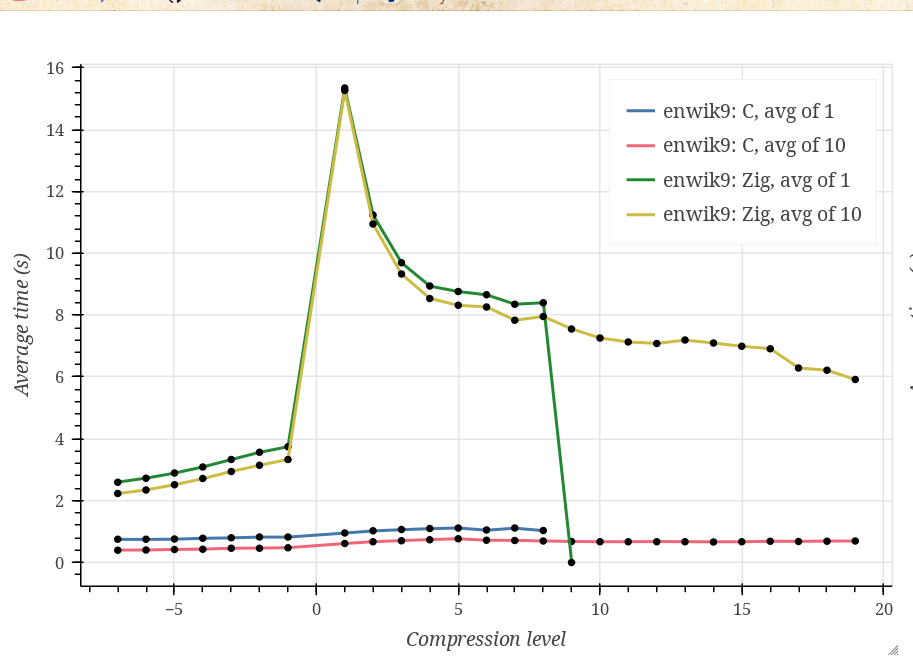
Compression levels go from -7 to 19 because the current Zig Zstd implementation does not support the ultra compression (20-22) levels, as far as I understand.
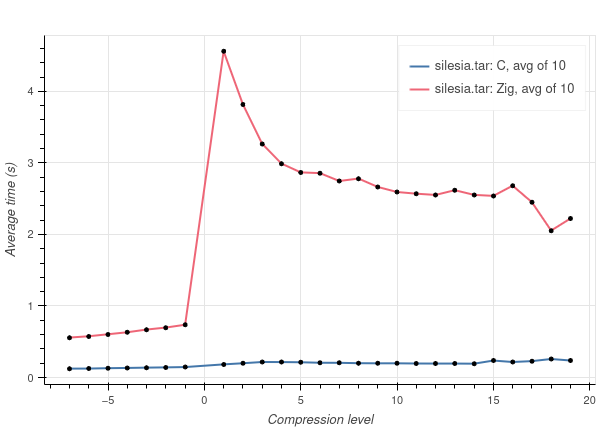
As you can see, Zig performs significantly (~10 times) worse on every tested dataset, and I can’t tell whether this is expected. Also, the Zig curve looks strange, having a huge spike at compression level 1 and rapidly decreasing at higher compression levels.
- Datasets I used are Silesia corpus, enwik9, and Linux kernel v6.19-rc7 sources. The first is used in the lzbench, which is referenced on the Zstd implementation GitHub page, while the other two just seemed reasonable choices, although I don’t have a strong justification for them.
- The issue proposes either adding a benchmark utility (which I assume would look pretty much like lib/std/hash/benchmark.zig), or adding a benchmark to gotta-go-fast.
Gotta-go-fasthasn’t even been ported to Codeberg yet and hasn’t been receiving any updates for 3 years, so I’m leaning towards implementing a standalone benchmark utility similar to std.hash. - I’m currently building the Zstd master branch with standard make options (which default to -O3 optimizations), then linking the produced library statically with the Zig executable, and building it with -Doptimize=ReleaseFast. All benchmarking is performed in Zig using the following code snippets (
czstd.decompressis a wrapper aroundZSTD_decompress):
/// Decompress ZSTD compressed bytes to out n times with libzstd.a and return total time elapsed in seconds
fn benchC(compressed: []const u8, out: []u8, n: usize) !f64 {
var timer = try Timer.start();
for (0..n) |_| {
_ = try czstd.decompress(out, out.len, compressed, compressed.len);
}
const elapsed_ns = timer.read();
return @as(f64, @floatFromInt(elapsed_ns)) / time.ns_per_s;
}
/// Decompress ZSTD compressed bytes to out n times with zstd.zig and return total time elapsed in seconds
fn benchZig(compressed: []const u8, out: []u8, n: usize) !f64 {
var timer = try Timer.start();
for (0..n) |_| {
var writer: io.Writer = .fixed(out);
var comp_reader: io.Reader = .fixed(compressed);
var zstd_stream: Decompress = .init(&comp_reader, &.{}, .{});
_ = try zstd_stream.reader.streamRemaining(&writer);
}
const elapsed_ns = timer.read();
return @as(f64, @floatFromInt(elapsed_ns)) / time.ns_per_s;
}
There are, of course, a lot of other options for building things for benchmarking. For example, I could build a C binary and a Zig binary and benchmark them with external tools, or benchmark the C implementation in C, and the Zig implementation in Zig. I’m not sure whether it matters.
-
As you can see, I include
io.Writerandio.Readerinitialization inside the timed section of the Zig implementation. I’m not sure whether the compiler fully optimizes this, but at least it should have a very minor overhead. -
I run each test case 10 times, and verify correctness only once at the end.
Benchmarking host specs:
- Gentoo Linux, x86_64, AMD Ryzen 5 5600X
- Zig 0.15.2 binary
- Zstandard v1.5.7
Git repository with current state of work. It contains short README on how to reproduce results.