zisp is a proof of concept that asks how far Zig’s compile-time machinery and the new labeled switchcontinue syntax can push parser generation. The project starts from high-level PEG (Parsing Expression Grammar) declarations and lowers them, at compile time, into tightly-specialized VM loops that read more like hand-written interpreters than generic parser combinators.
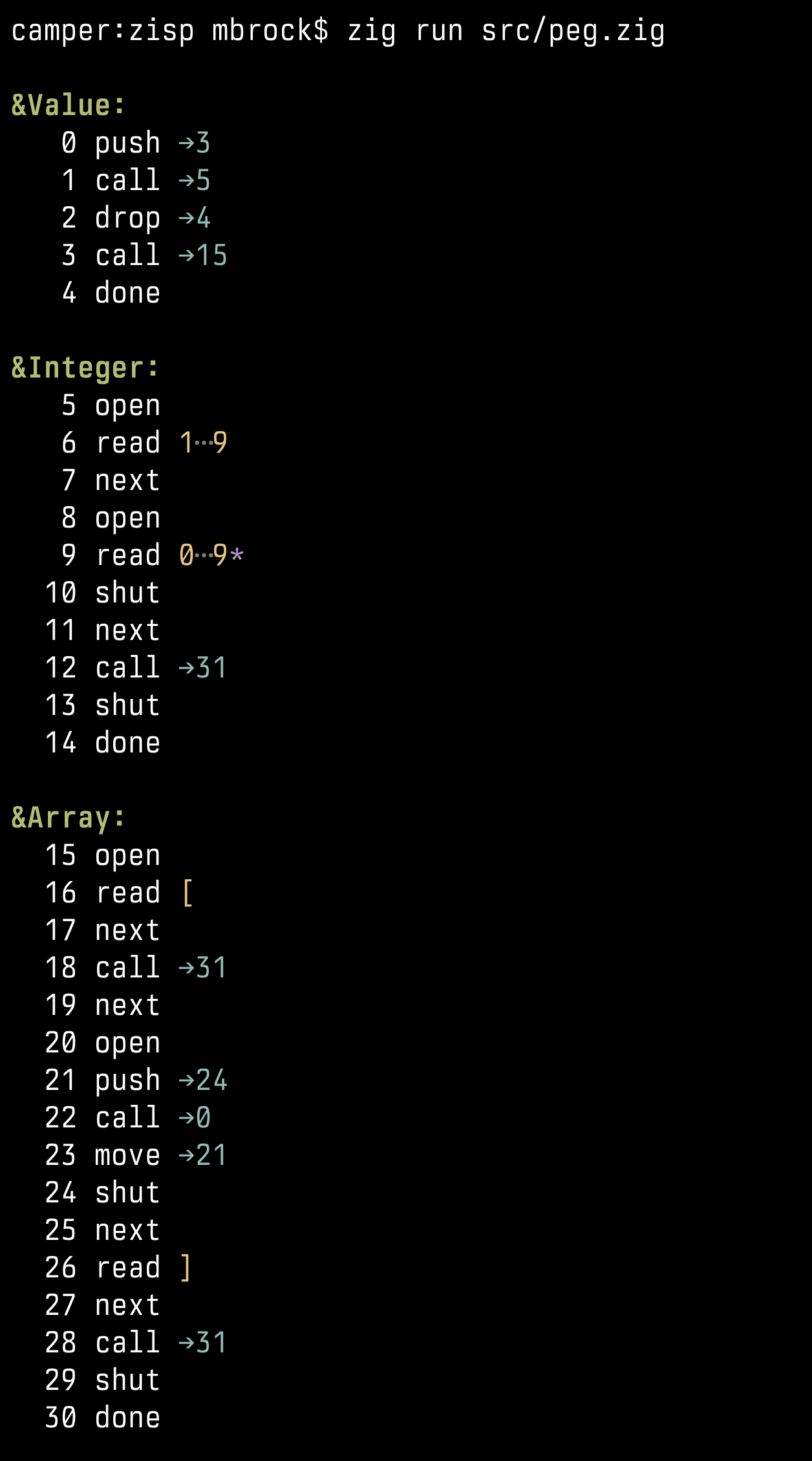
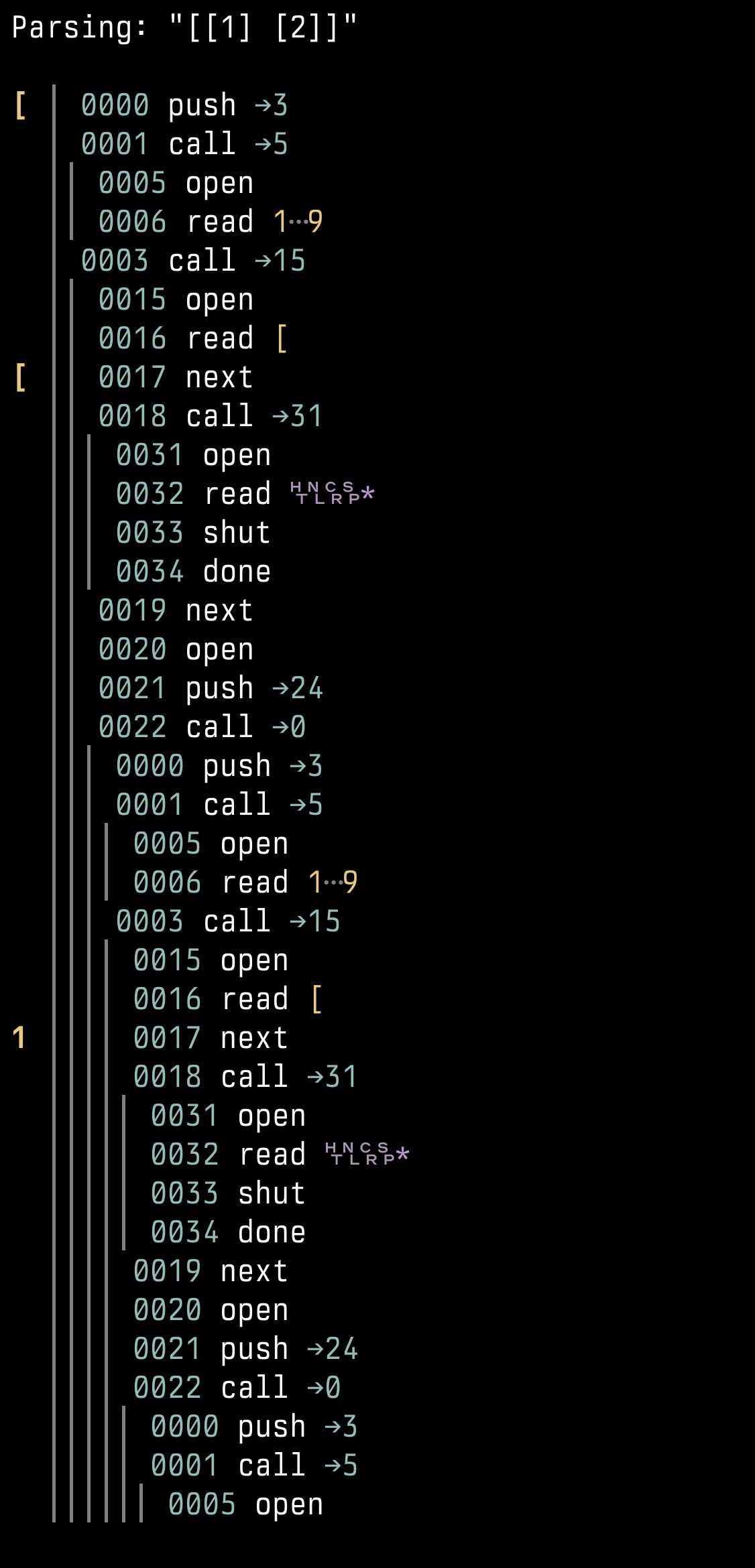
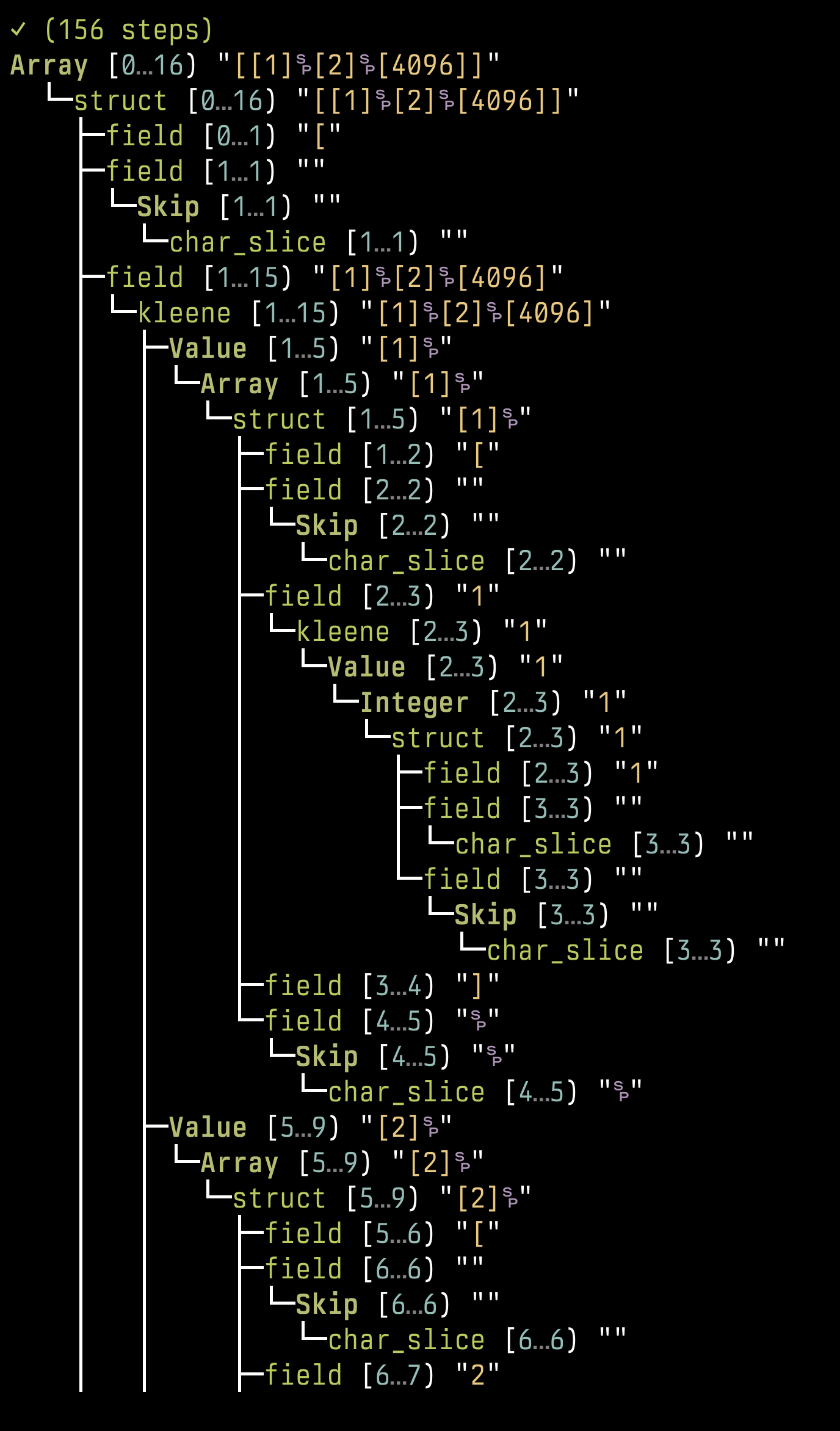
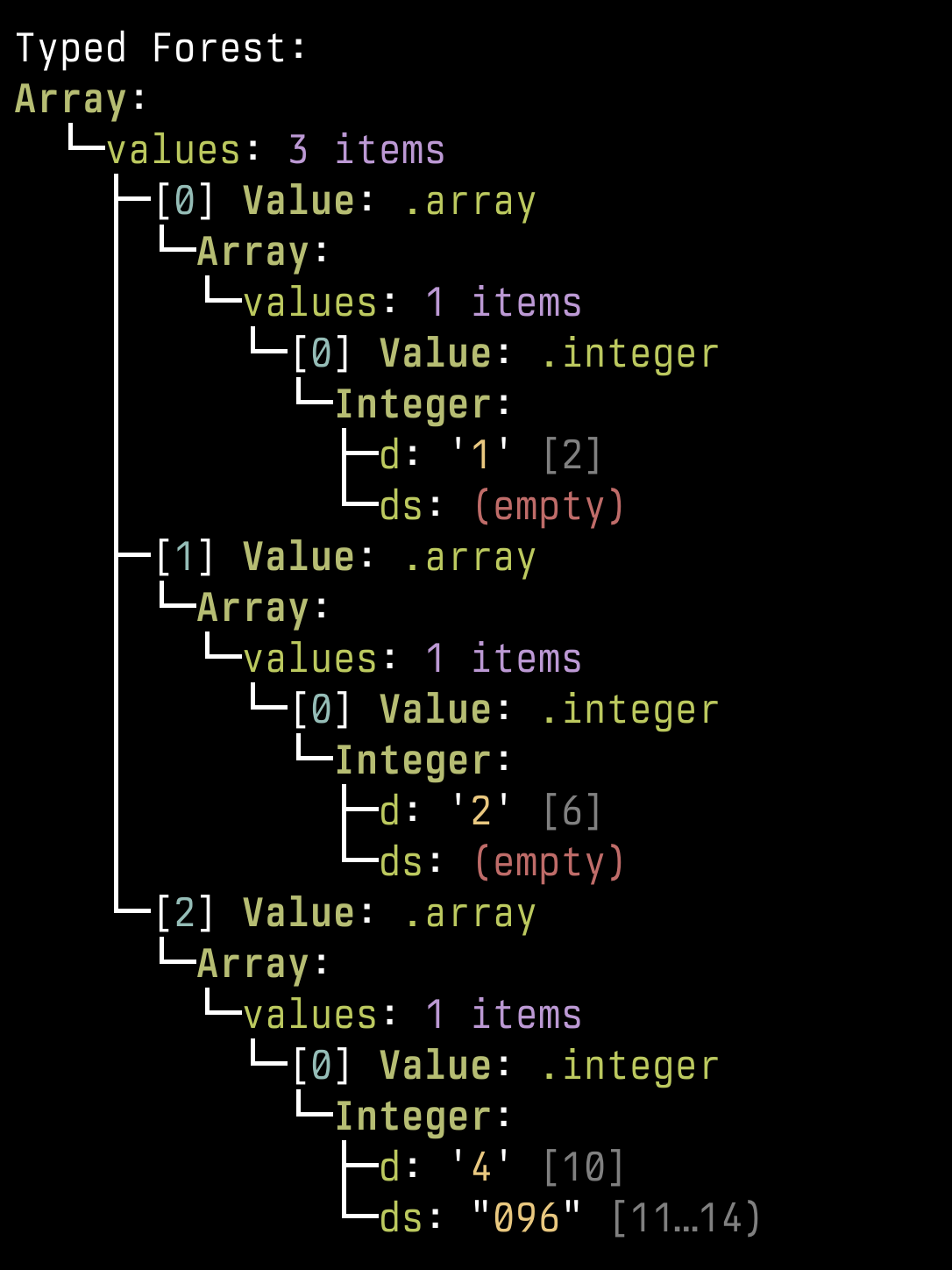
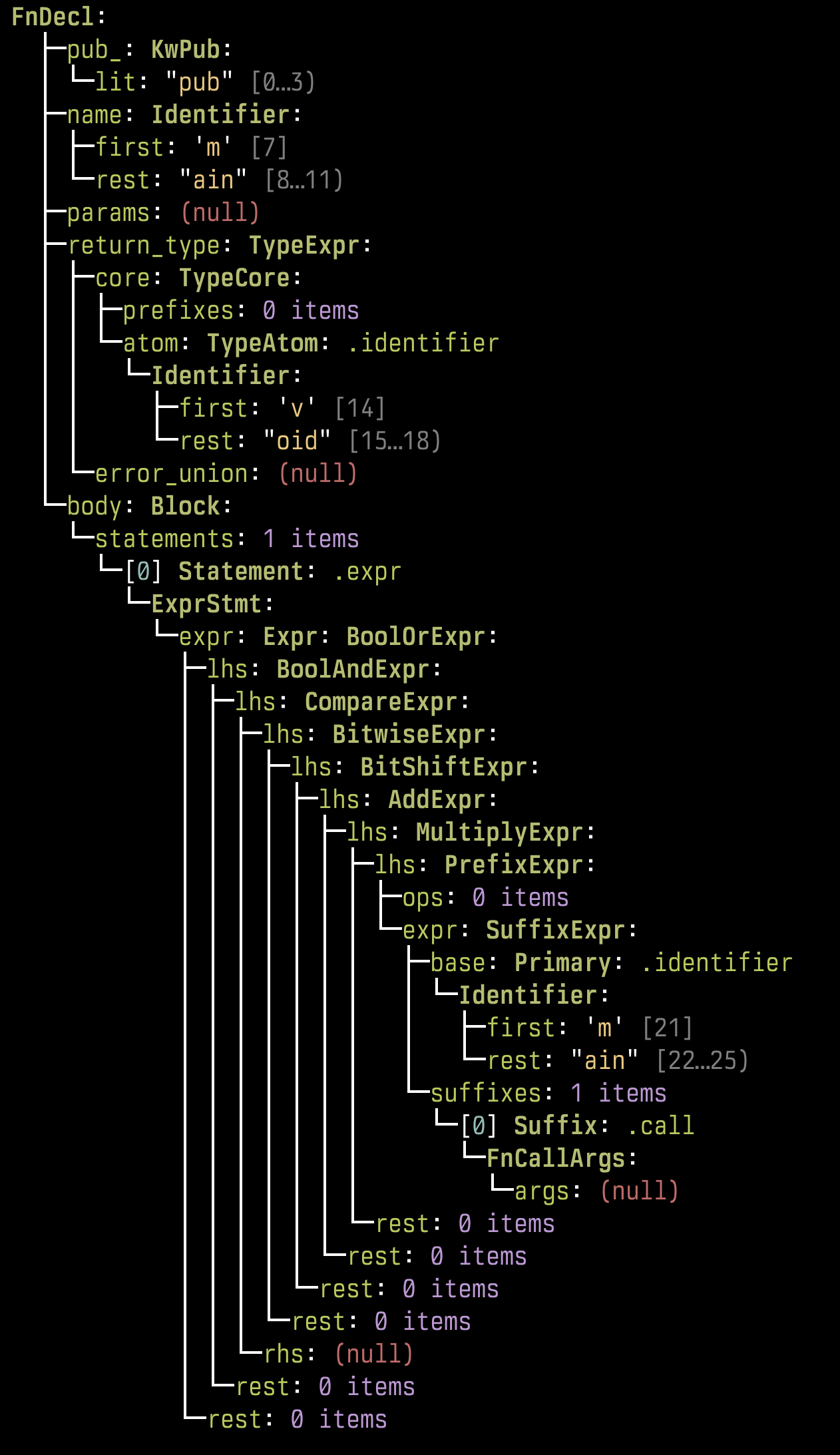
The VM builds a “typed forest”: every grammar rule owns a dedicated growable array, and siblings for a rule end up stored contiguously. That layout makes it cheap to gather a rule’s results and to reinterpret slices as strongly-typed structs/unions when you walk the AST later. In the demo run the root rule is Array , whose values field is emitted as a Kleene list of Value nodes; each Value lowers to either an Integer or another Array , and you can see the nesting clearly in the forest dump.
Because the VM bytecode is baked during comptime , the “interpreter” that ships in the binary already knows the exact instruction stream. VM(G).next gets monomorphized for the grammar, the opcode array becomes a constant, and the main loop lowers to one giant switch /jump-table keyed on the instruction pointer. In other words we don’t even switch on an opcode enum at runtime; we switch on the literal IP and jump straight to the inlined code for that specific instruction.
// Pseudocode, but this is the flavour LLVM ends up with.
vm: switch (ip) {
0 => { // read '['
if (self.text[self.sp] != '[') return error.ParseFailed;
self.sp += 1;
continue :vm 1;
},
1 => { // call Skip rule
try self.calls.append(.{ .return_ip = 2, .target_ip = 31, ... });
continue :vm 31;
},
2 => { // next field, etc.
...;
continue :vm 3;
},
else => return;
}
Oh man this overlaps so much with a silly idea which I’ve been carrying around for much too long with no idea yet if it’s feasible… e.g. something similar just in the area of computer emulators.
E.g. what if I could describe the components of an emulator (e.g. its hardware chips and how they are connected to each other) in some highlevel DSL similar to Verilog or VHDL, and instead of generating an FGPA the output would be a highly specialized state machine as a single big monolithic source file that’s completely specialized for an entire emulated system (despite being built from “standard chip descriptions”).
Currently I’m at the point where I’m doing code generation for some chips (ok, only the CPUs), and then describe via Zig comptime code how the system chips are connected to each other via their in/out pins (which saves quite a bit of runtime bit-shuffling code). But the next step would be to have some sort of high level definition for an entire system (basically the computer schematics as code) which is then used to generate an emulator that’s efficient enough to run in realtime - and at the same time that same information could be used to create all sorts of visualizations and debugging tools…
Anyway… no time for that for a while unfortunately
Actually generating Zig code and hooking it all up through the build system may save your sanity—my approach doesn’t even really help with LSP completion—but who can resist the comptime nerdsnipe?
Nice to hear! I should mention the approach is inspired by the Lua PEG VM and the paper describing it, though it separates its call stack from the backtracking stack in a way that they don’t do. As the README mentions, there’s a port of Zig’s own grammar that isn’t far from complete, but I redesigned the whole grammar API and haven’t rewritten the Zig grammar thing yet.
The old variant is in pegvm.zig and may be interesting because in some ways simpler but has some horrible, amusing problems: grammar rules are actually arrays of opcodes, and a call to another rule is written as a pointer to that rule array, which means Zig has to know the concrete opcode size of all preceding rules in the grammar, otherwise the compiler segfaults. I tried doing it like this so the Zig LSP could accurately rename rules, which doesn’t work properly through the DeclEnum approach, but I don’t think it’s worth the segfaults.
Anyway I hope to port over the Zig grammar to the new API, maybe tomorrow, and that’ll be a good realistic way to exercise the implementation; my goal is to be able to parse most of Zig std.
That’s an interesting choice, never occurred to me.
I know the pain, believe me. A port of that project was the first thing I tried tackling in Zig, and it’s been on the back burner while I shave a few yaks the size of mountains.
Hah, cool! I was experimenting with having grammar rules as function declarations rather than just const declarations, where the function parameters specify the subpatterns, and the return value becomes the node’s type in the final tree—like semantic actions or whatever—but I couldn’t really make it work nicely. Now, instead, since the rules are usually struct or union(enum), types, you can just define functions on them like meaning(self: @This()) !u32 {...} or whatever, and call those after the parser’s work is done…
Oh, another nice feature that comes for free from comptime is that the parse function can either run to completion as a loop or, if you want, do a single step and return the next IP. The trace feature uses that stepping mode to show intermediate steps, and you could use it for debugging, or even for making it preemptible and event loop friendly by e.g. running 1000 steps at a time, or whatever. Thanks to comptime, the VM code isn’t duplicated, it just does a comptime if to decide whether to continue or return; the pattern is very literally:
This is basically what Verilator does (generates a C program that is an emulator of your specific Verilog program). Also how the Mill’s emulator works (you express the assembly with C++ templates and then compile the C++ to produce an emulator of that specific program).
I started porting over the Zig grammar in ziggrammar.zig, it’s working to some extent. Those meaningless precedence wrapper nodes are painful to see in the syntax tree though, and the raw parse tree feels even more ridiculous.
This is really cool. I like how you are using zig itself to describe the grammar. I have similar (stagnant) project that aims to do something similar, but it compiles ragel -like language instead.
Since JLpeg was based on LPeg, it was also oriented around captures. My solution to this problem has always been that some rules capture, and some rules don’t.
That lets me drop parentheses and keep groups, never capture whitespace, and fold out intermediate grammar rules during parsing. Of course it also means keeping a capture stack, but that’s probably ok. If you were filing captures down to the bare minimum, it could probably be a set bit on call frames.
Instead of improving the actual parser thing, I’m glad to announce that after learning to use Zig’s @Vector with @splat and @select, I figured out how to implement the tree printing code with SIMD—on modern x86 just eight AVX-512 instructions render 32 tree levels to a whole array of UTF-8 box drawing characters… so, at least that’s fast…
Ahh, I realized that the code is as good or even better without any @Vector or bit casts or anything—when both the UTF-8 patterns are 4 bytes each, this code that explicitly loops over a bitset and @memcpys into the buffer gets optimized into the same splat/blend SIMD code!
It even makes a nice dispatch on the len to choose one of like four different specialized paths, code is great on both Tigerlake and ARM64. Autovectorization is more ambitious than I would have guessed!