Where did you get the mechanics?
So many cool project ![]()
I’m continuing to tinker with my Markdown toolset Zigdown (sorry for using zig in the name, I was not terribly creative when I started the project, and I also didn’t expect it to last this long, but here we are ![]() ). I use it on a near-daily basis to pretty-print documentation at work (either in the console, or in Neovim, or the browser via the
). I use it on a near-daily basis to pretty-print documentation at work (either in the console, or in Neovim, or the browser via the serve feature), and I also use it for rendering my personal website, because why use a fancy web framework when you can roll your own pseudo-static HTML site?

I also created a password manager, Loki (I’d like to think I’ve gotten better at naming things), which arose from my love/hate relationship with KeePassXC and Dropbox. It’s become my daily-driver password manager, and I run the server on a Raspberry Pi in my living room, allowing me to seamlessly (and without data loss!) sync my passwords (and notes) among all of my devices.
Loki AI Use Disclaimer
Loki started a couple months ago as “well I have to use AI tools at work, and they seem kinda useful; can I use them to bootstrap an idea I’ve been putting off due to effort?” and the answer seems to be a resounding “yes”. The project started off fully vibe-coded to get to the PoC stage, and once I proved to myself the idea was sound, I started “taking ownership” of the codebase, starting with the most critical bits (encryption and network-based synchronization), and then later moving on to the TUI (less critical, so has received less effort). I believe the storage and networking are secure based on my limited knowledge of cryptography and authenticated encryption, but I am by no means an expert, so use at your own risk.
I also vibe-coded an Android version (honestly, super cool that you can use Zig to develop apps for your phone!), and that remains pure AI slop, which is why I haven’t bothered sharing Loki here before now. I have no real interest in spending my time learning Java and Android, so ![]() I’ll take the slop if it means I have a functional tool for my personal use.
I’ll take the slop if it means I have a functional tool for my personal use.
I know there’s a lot of strong opinions on AI here (and for good reason), but I’m now in the camp of “well, these tools are kinda useful, and they’re not going anywhere, so might as well use them when it makes sense”.
P.S. - If anyone knows an artist who could create a real logo for Loki for me instead of the silly AI-generated logo I have now, I’m all ears!
14 Likes
Many in the Zig community have commissioned work from Joy Machs. I did too a few years ago, and it was a great experience.
4 Likes
neutils
It’s a monorepo of single purpose CLI tools, all written in Zig. Most of them use @JacobCrabill’s fantastic Zigdown library for terminal rendering.
| Tool | Description |
|---|---|
urlparse |
Parse and display URL components |
urlencode |
Percent-encode a string for use in URLs |
mbox-diff |
Find new emails between two mbox files |
mbox-index |
Build an index of an mbox file by message identifier |
mbox-gen |
Generate synthetic mbox files for testing |
og-check |
Fetch a URL and render its OpenGraph / Twitter Card metadata |

All of these tools have been born out of either a need or some curiosity.
Most recently I have been working on og-check that can be used to check a website’s OpenGraph / Twitter Card metadata in the terminal. Images will be displayed if your terminal supports Kitty graphics protocol.
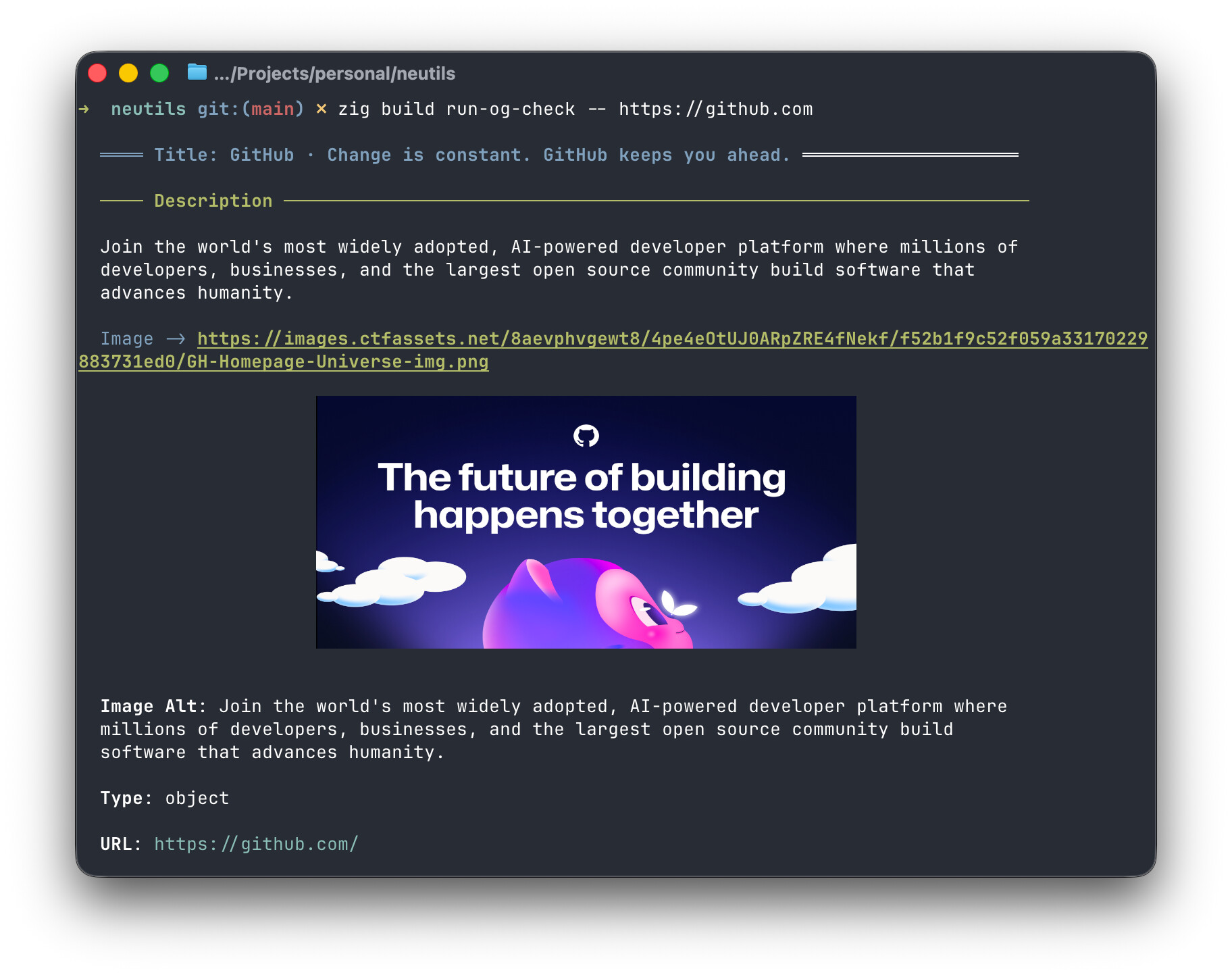
I’ve written about a couple of the tools on my blog.
As part of working on og-check, I am in the throws of writing a markdown “builder” that is modeled off of std.json.Stringify
10 Likes
I’ve changed the name to Azoryn, to better match what it is for, and not what language it uses https://codeberg.org/Moortu/Azoryn
2 Likes
I feel you, I have rebranded because they are kinda right.
I’m contracting with a friend to help build out additional functionality in his Zig+Python implementation of the VDB file format, which is used mainly in the VFX world, particularly to represent dynamic topology for things like clouds, explosions, etc.
Using Zig+Python and building in Numpy interop makes it much easier for folks outside the VFX world to use his project (the canonical VDB implementation is in C++ and appears to need Docker for building), which has been really exciting for him so far. He’ll be presenting about it at PyCon this year ![]()
So far I’ve managed to dramatically improve memory use (in my test case: 159% reduction in RSS) and speed (in my test case: 25% reduction in wall time) while also significantly reducing the disk size (by 50% or more, iirc) of the created .vdb files by taking advantage of more of the affordances of the data structure.
Now that 0.16 is out and my day job (i’m a math professor) is about to dial back in stress for the summer, I’m excited to get back into hacking on pollux, which is a bit like Python’s Trio for Lua, but wrapping std.Io.Evented. I’m also poking around with Vulkan in hopes of eventually making a game.
9 Likes
I implemented a serialization/deserialization library for the SomeIP protocol (a binary communication protocol used by the automotive industry) in Rust based on the SerDe data model. That made me realise how limited proc_macros actually are and when I heard of Zig and its comptime reflection, I was excited to try to implement something generic in Zig.
I was trying to stick to the protocol we are using at work, which is highly-over-engineered and a real pain. E.g. you can change the width of the length field of dynamic arrays, strings and unions. And they also have bit sized integers (which I haven’t yet implemented, but was also a reason to choose Zig, as this has language support).
It is just some hobby project to try out some stuff and get familiar with the language:
4 Likes
Full-blown DE (FreeBSD as prime target) via quickshell TopBar • charlesrocket
driven by dfs under the hood GitHub - charlesrocket/dfs: Config manager with a true two-way synchronization · GitHub
3 Likes
I’ve been working on a web framework in Zig (0.16) called Spider.
It started as a personal project to explore building web apps in Zig, and has been evolving as I use it in real applications.
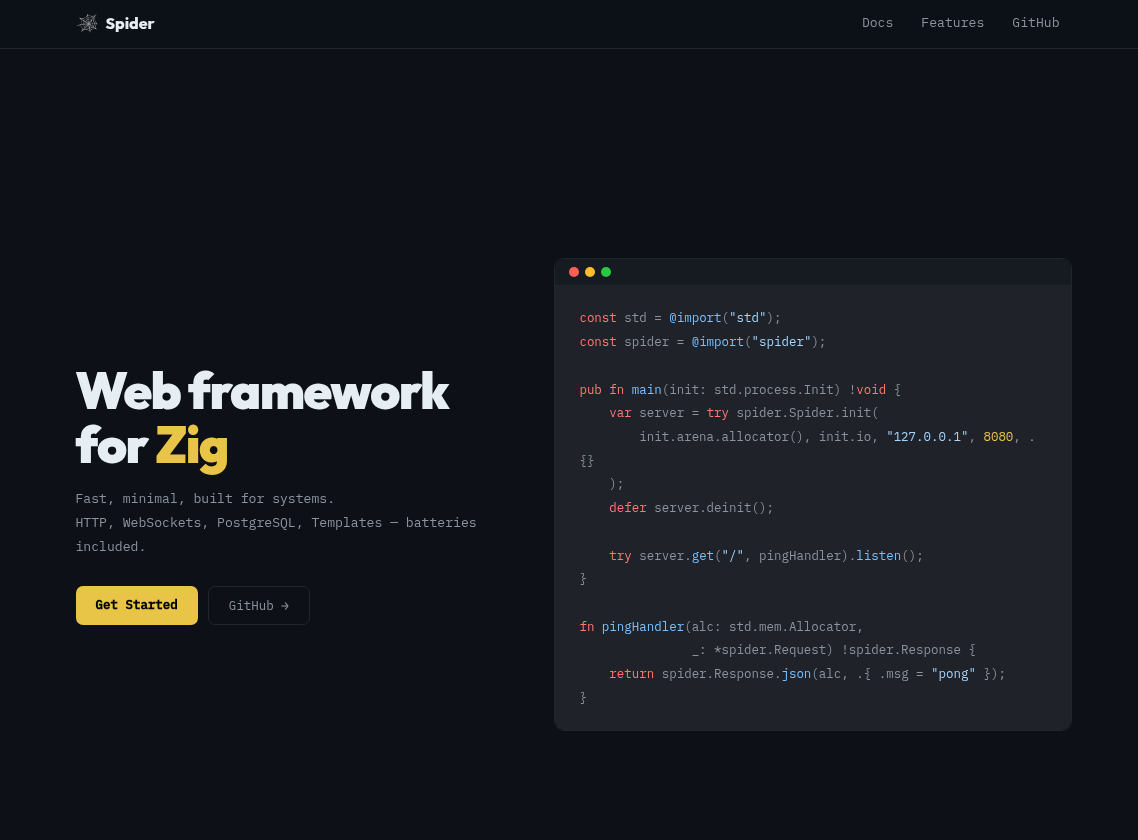
Some highlights:
- Built in Zig (0.16), no external runtime
- Full-stack approach: routing, templates, and database in one place
- Designed for simplicity and small/medium applications
- Used in production (Smoney running live)
- Starter kit (Spiderstack) for fast project setup
- WebSocket support for real-time features
I’m also building Spiderstack, a starter kit to speed up development with auth (Google OAuth), CRUD, HTMX/Alpine.js, Tailwind, and a basic app structure.
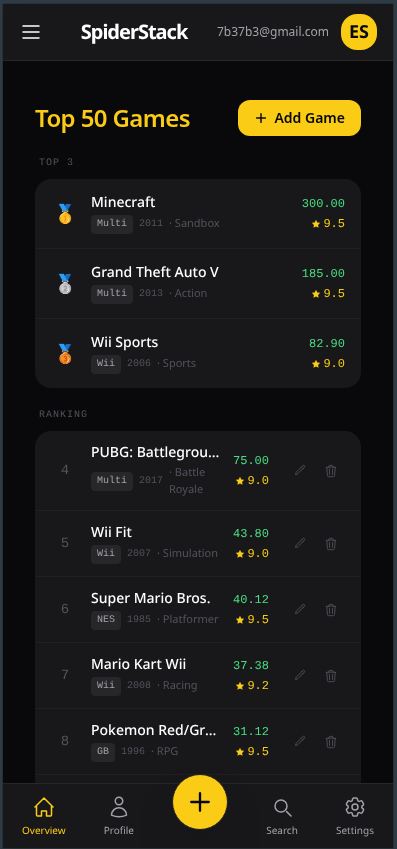
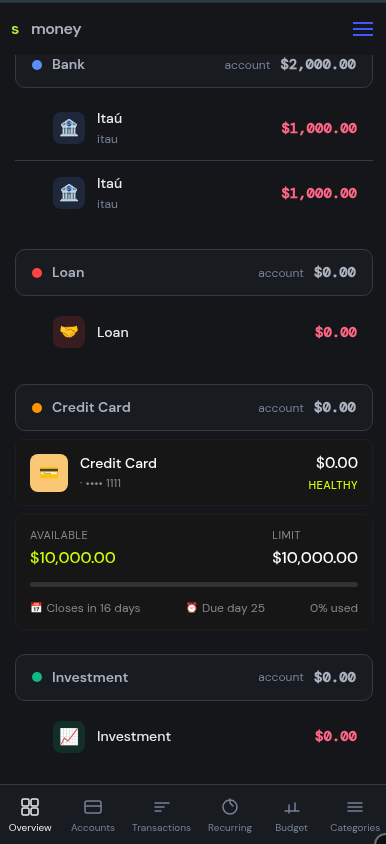
To validate everything, I’ve been using Spider in a real project called Smoney, a small personal finance app currently running in production.
Everything (framework, site, and apps) is built using Spider.
Links:
- Docs / site: https://www.spiderme.org/
- Example app (Smoney): https://smoney.spiderme.org/
- Spider repo: GitHub - llllOllOOll/spider · GitHub
- Spiderstack repo: GitHub - llllOllOOll/spiderstack · GitHub
I’m still iterating on the design and APIs, and I’d really appreciate any feedback — especially around architecture and developer experience.
11 Likes
I’m working on an implementation of Depth-Dependent Halos (uni related). It describes a technique to visualize dense line data e.g. from air flow simulations or tracts of white matter in the human brain (which can apparently be measured using some advanced MRI techniques).
It works by surrounding each line with a white halo which is displaced further ‘back’ the further it’s away from the center of the line to achieve an effect like this:
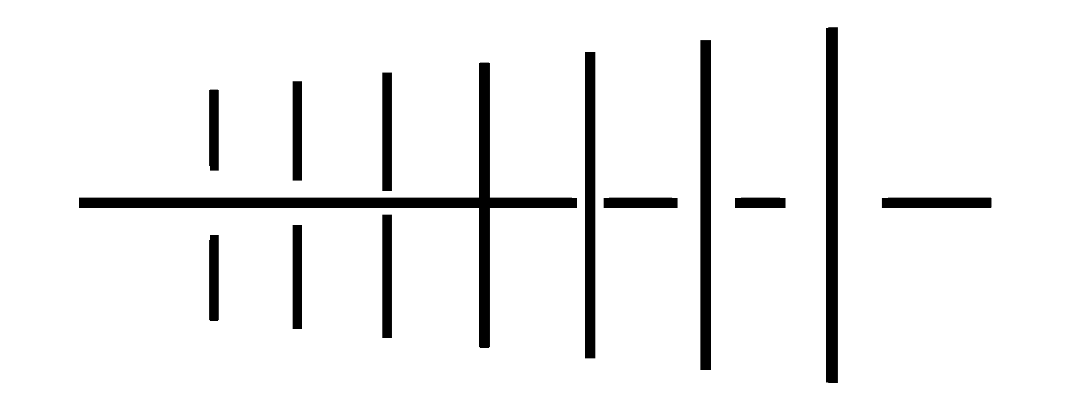
and produces some pretty cool visuals:
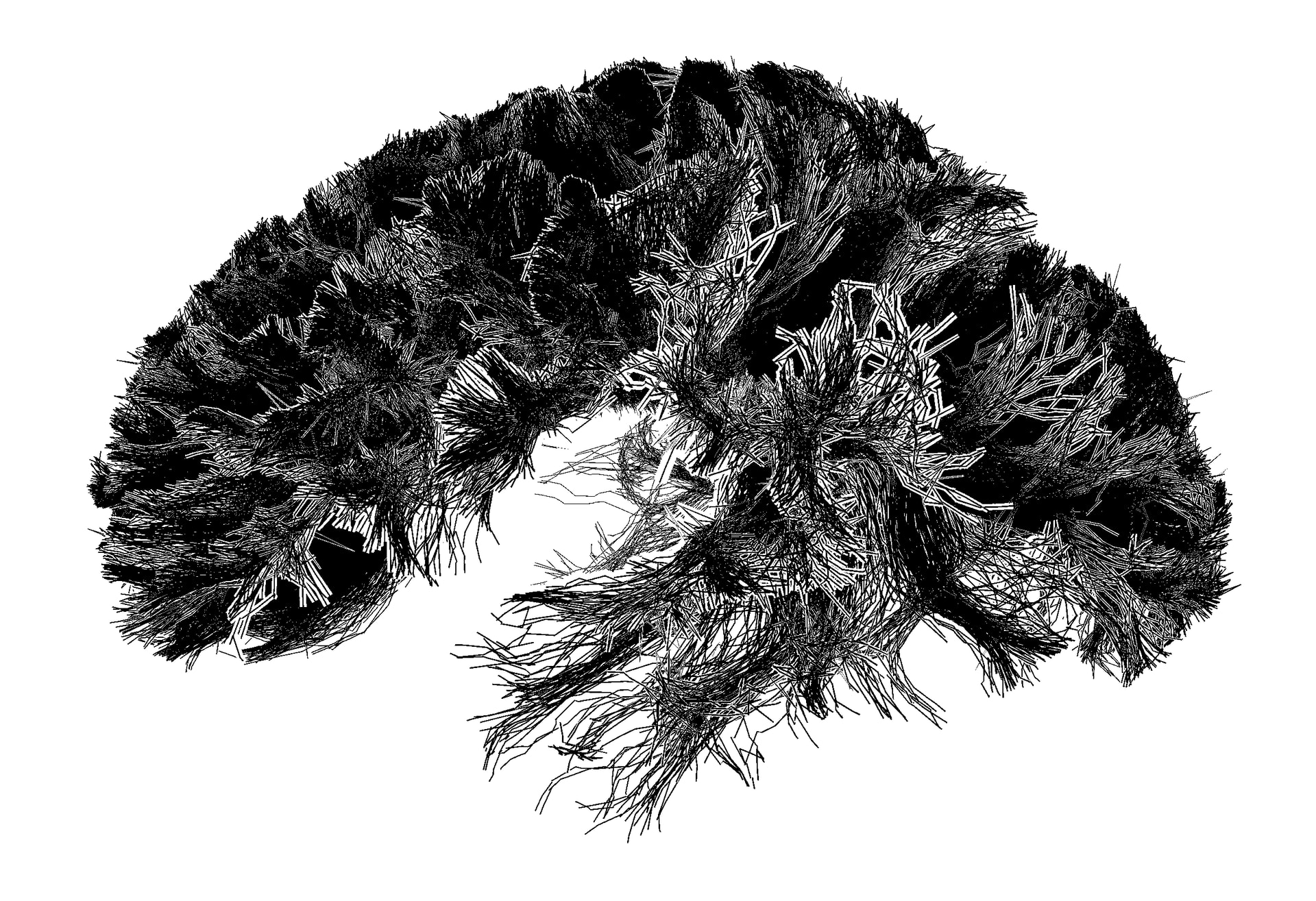
I’ve taken this as an opportunity to learn some basic graphics programming which I’ve been meaning to do for quite some time anyway. It uses sokol by @floooh which has been a pleasure to work with so far.
There are still some TODOs I want to tackle eventually, but it’s totally usable in its current state. You can check the project out here: https://codeberg.org/justusk/depth-dependent-halos
If you want to try it out locally (zig 0.16.0 required):
zig build run -Doptimize=ReleaseFast -- ./testdata
This will open a native 3D viewer that lets you rotate and zoom however you like and a little GUI window that lets you tweak some parameters and load the next model.
To get a nice result you might have to play with the params a bit, the paper recommends a ratio of 1:[4..8] for w_strip:w_line (though I’ve found that lower ratios often look better for this particular data set) and enabling+lowering density is probably a good idea (especially wrt fps) since the sample data I was able to find is extremely dense.
16 Likes
TBH, while I recognize that namespace pollution is a thing, but I don’t quite get what you are really asking.
Are you objecting to people attaching .zig suffix or zig- prefix to the repository name (or both, which i haven’t seen but would make me chuckle)? As if, I name my project zig-sqlite, then everyone thinks this is the official sqlite repo for zig? (Heck, i think for sqlite there are already like 2 independent packages.)
O are you talking about the thing part? I.e. we should just not use short, generic names for the sake of not polluting the namespace for someone who actually has a project that more closely fits the semantic of the word? As if I name my project zig-foo without having ambition to solve all possible “foo” problems?
I’m probably missing something, but I feel that as is, your plea is rather vague, and having vague requests (however polite and well-meant) seems unhelpful. Even more so to those who would like to be a good citizen and oblige.
Personally I always find myself anxious and overthinking naming things before bringing them to light – often because I already don’t want to name-pollute and/or mislead people. Especially also since basically all of my projects are just for me, I have no ambition for my project to be “the thing”. Usually when I’m publishing things (esp. here) it’s mainly because I wish for feedback from other programmers about the code.
I used to check for conflicts with Debian & Fedora repos and eg. pypi–that’s how one would catch the big things, but that’s not enough nowadays since most things don’t get there and there’s no universal list of projects (and there probably shouldn’t be). There’s a lot of niches as well, eg. who would guess that there exists a WM called “river” and thus using “river” for a project name might be ambiguous?
IMHO it’s not possible to set objective criteria for good name, especially independently of a centralized index.
1 Like