I have been trying to implement an index over Ptr approach for a certain struct I am desiging but I wanted to see if I had been missing something very important here because this seems too verbose to me.
My main concern is that I plan on making some of these function calls at 144Hz, and making the self.instance() call each frame seems a waste of CPU, at the same time its required to avoid any segfaults.
I am aware that threads don’t usually need an index handle approach (considering using plus 5 threads is not very compatible across devices, so I am not saving much space), I am just using this as an excuse to see how to implement this approach.
pls note this is a very incomplete implementation when it comes to intended behaviour of the methods. Also, feel free to throw any suggestions in style or code.
// -------------------------------------------------------------------------------------------------
// Class Declation
// -------------------------------------------------------------------------------------------------
const Thread = @This();
.
.
.
/// or create
pub fn generate() !ThreadHandle {
if ( buffer.alive ) |thrds| {
for (thrds, 0..) |instance, idx| {
if (instance.is_spot_taken) { continue; }
else return ThreadHandle{idx};
}
return error.OutOfMemory;
} else { return error.NotInitialized; }
}
// -------------------------------------------------------------------------------------------------
// Handler Class
// -------------------------------------------------------------------------------------------------
const ThreadHandle = struct{
// ---------------------------------------------------------------------------------------------
// Fields
// ---------------------------------------------------------------------------------------------
handle_indx: i8, // indx > 0 : alive buffer orelse index < 0 : dead buffer index
// ---------------------------------------------------------------------------------------------
// Meathods
// ---------------------------------------------------------------------------------------------
fn instance(self: *const ThreadHandle) !*Thread {
if (self.handle_indx < 0) { return error.InvalidInstance; }
const slice = buffer.alive orelse return error.NotInitialized;
return &slice[self.handle_indx];
}
pub fn terminate(self: *const ThreadHandle) !void {
const inst = try self.instance();
inst.status.store(.termination_requested, .release);
}
pub fn signalAsleep(self: *const ThreadHandle) !void {
const inst = try self.instance();
inst.status.store(.asleep, .release);
}
pub fn signalAwake(self: *const ThreadHandle) !void {
const inst = try self.instance();
inst.status.store(.active, .release);
inst.time_stamp = std.time.nanoTimestamp();
}
pub fn isStatus(self: *const ThreadHandle,stat: Status) !bool {
const inst = try self.instance();
return (inst.status.load(.acquire) == stat);
}
/// put inside the while expression
/// must be called inside the thread only
pub fn loops(self: *const ThreadHandle) !bool {
const inst = try self.instance();
if (inst.status.load(.acquire) == .termination_requested) {
inst.status.store(.terminated, .release);
return false;
}
inst.gate.wait();
inst.time_stamp = std.time.nanoTimestamp();
return true;
}
/// insidea while loop in the main thread, make sure to sleep optimize the loop at 20Hz or
pub fn getStatus(self: *const ThreadHandle, frames_lost: ?*u32) Status {
const inst = try self.instance();
const now = std.time.nanoTimestamp();
const last = inst.time_stamp;
const diff = now - last;
if (diff < 0) return .active; // clock glitches only happen if the frames were too close
const frames_lost_: u32 = @divTrunc(diff, self.loop.frame_time);
if (frames_lost) |val| { val = frames_lost_; }
const stat = inst.status.load(.acquire);
if (@intFromEnum(stat) < @intFromEnum(Status.active)) return stat;
if (frames_lost_ < cfg.max_frames_skipped ) { return .active; }
else { return .non_responsive; }
}
};
Wait, is it really that small? Remember that this logic renders every function an error union returner, so it kind of drives me crazy that every function would need to be a try or a catch statement on a high-frequency loop.
Another Problem I have is with the fact that every function is an error union just because of the instance() method. This really breaks the point of using an index to save 7 bytes when there is an extra 2 bytes of error union attached to every method called.
Generally when applying this pattern you will indeed often make the access on demand (which often is justified since it is often more cache-friendly than pointers), and with x86 memory addressing instructions, the cost is often quite low.
If possible I would also recommend make it fixed size buffer in a global variable (in this case you already have added a hard limit of 128 entries), or if you cannot determine a reasonable upper bound and are worried about memory usage, you can also use other tricks (reserving pages with mmap/VirtualAlloc) to ensure that you can resize the array in-place. This avoids all the headache of buffer resizing or initialization (which I assume is the segfaulting you refer to)
Side note, but I’d recommend to use packed structs to encode this behavior:
The error union of course adds extra cost, however I would suggest to use assertions instead. Calling these functions on an dead entry or buffer seems to me like a programmer error, and not something that you expect to happen in a normal execution flow.
I think you’re making a lot of performance assumptions that are giving “paralysis by analysis” when you’d be better off trying something, measuring, trying something else, etc. I often feel that way when I perceive rewriting the code to be a pain in the ass, but it can also save you time if the brain dead simple thing is fast enough.
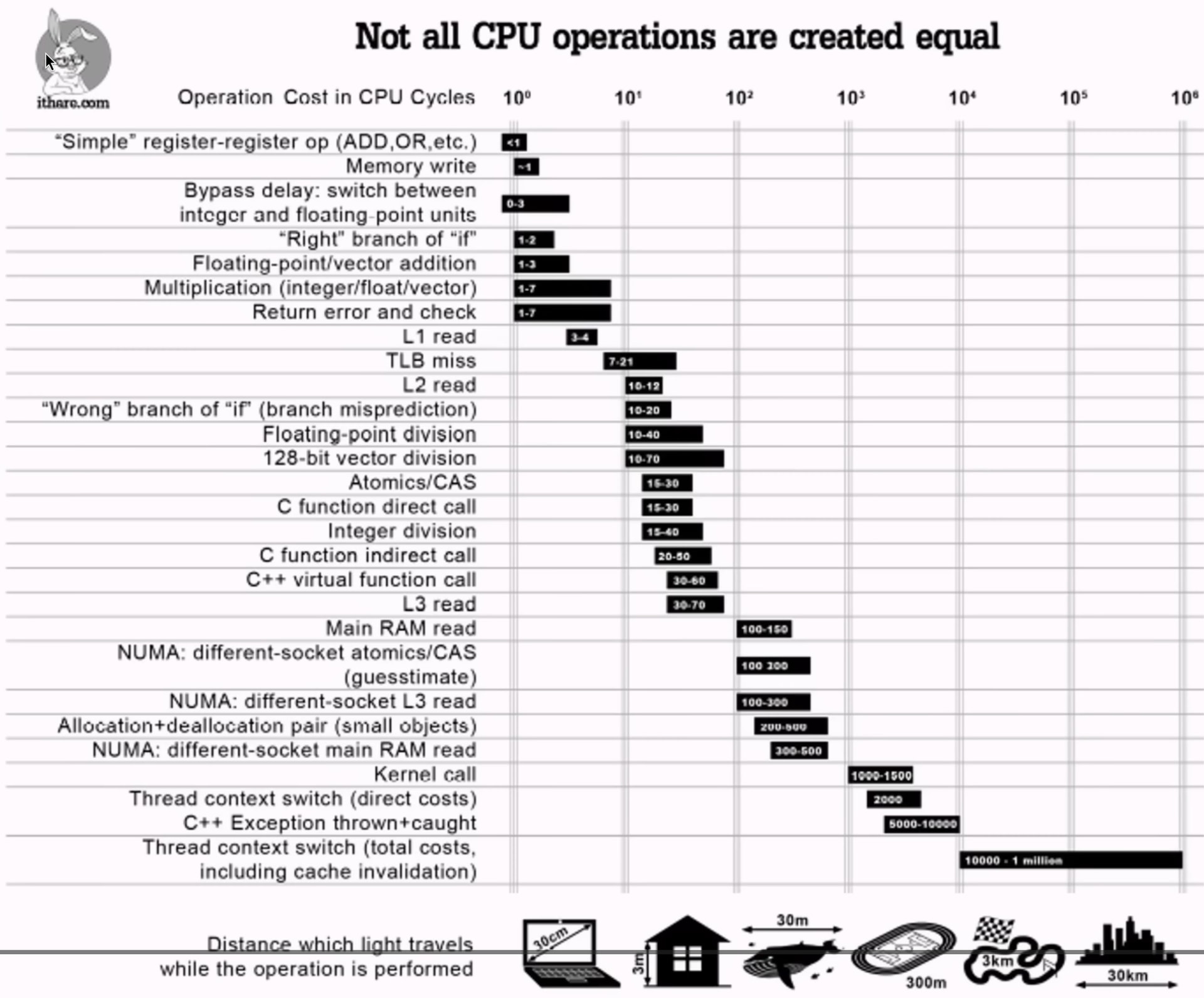
Stepping back for a second, 144Hz is 6.9ms per iteration. A single “add” instruction is on the order of 1ns, so you have a roughly 1 million instruction budget if you don’t account for latency due to memory access, system calls, etc.
Optimisation choices like this can be non-obvious. Packed structs mean (normally) a smaller memory footprint, which can mean better cache utilisation. However it’ll take a few extra instructions to unpack fields. Which one will cost more? Cache misses or extra instructions. I’d normally favour minimising cache-misses as those are very expensive.
I’ll borrow a table from one of AK’s talks here (Note it’s logarithmic):
This approach leads to cargo-culting efficiency, there is no sensible answer to your question.
If you’re curious about the machine code a construct will generate, Godbolt is your friend. My experience is that using packed structs for bit-twiddling is a clear win: the code is normally equivalent to what I would do manually, and much easier to follow.
Just don’t make up heuristics like that. If you need to know, check.
Packing/Unpacking a field from a packed struct would normally be an shift + an OR (pack) / AND + a shift (unpack)
I was trying to come up with a Godbolt example, but the Zig compiler keep optimising all the overhead or packing and unpacking away.
I’d very much agree with @zmitchell & @mnemnion though. You can go crazy trying to predict this stuff. Trying stuff with a few toy examples and measuring them can give you more useful information for your case than any analysis will.
In this particular case, there is no difference between using a sign bit and using a packed struct, since both have the same layout, so both have to test the most significant bit and do something, or take the remaining bits. The packed struct does require a shift and and in debug mode, but the optimizer can trivially determine that checking the first bit is the same as checking the sign, and if the first bit is zero then it doesn’t need the and.
There is no reason to use a magic sign bit when you can use a packed struct, as long as you lay it out correctly and use sufficient assertions to clarify your knowledge, the compiler can practically always optimize them to the same assembly code.