Experimenting with the build system on one hand and Linux io_uring on the other. subzed is a very basic HTTP/1.1 web server that generates all the HTTP responses for your static site, embeds them into the binary executable, and serves them at blazingly fast speed from memory. I got around 175k requests per second on a not-so-new Linux box.
17 Likes
This number is more or less in accordance with an epoll/uring comparison (echo-server):
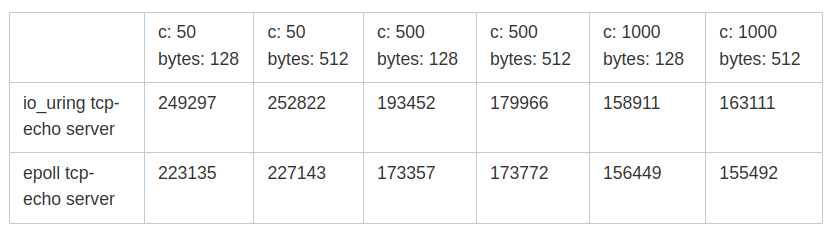
Taken from here (in Russian, 2021)
Great, I’ve been wanting to learn iouring and this is great resource. Is the whole flow apart from parsing HTTP handled by kernel?
I think, it would be more interesting to use io_uring both for sockets i/o and for file i/o.
2 Likes
I was thinking about this and was confused for not finding any file iops, until I reread the first post. It might be actually faster using files as you can skip writing bytes to kernel (sendfile).
sendfile was a workaround invented with the purpose of reducing the number of user space ↔ kernel space data copying: “traditional” way to send a file assumes at least 2 transfers between the spaces, one is when we read a file content and the second when we supply this content to a socket API; sendfile eliminates redundant data copying. io_uring is a general mechanism for async i/o, whereas sendfile is just an optimized way of copying data between two file descriptors, it has not to do with async ops.
1 Like
Right, what I meant to say, since I’m unfamiliar with iouring API in general, is that I was hoping to find something equivalent to sendfile done with iouring so the whole connect, accept, send is done in kernel in a single syscall (or in few as possible).
me too ![]()
I think this might be useful. IMHO, asynchronous way of doing I/O requires total rethinking of an application architecture.
1 Like
Yes, it does combine multithreading with io_uring by having each thread have its own separate ring. The main thread only accepts connections on its ring and then passes the socket fd to the worker threads via a mutex-protected FIFO queue (basically a poor man’s channel).
This server doesn’t even read files ever. It just sends bytes directly from memory every time. The files are read by the build system, where they are cpmpressed if needed and prepared as canned HTTP responses placed in a ComptimeStringMap for fast retrieval.
2 Likes
This server is using the Zig standard library io_uring wrapper of the Linux io_uring low-level API. There are still some newer aspects missing that would in theory allow for zero syscall operation. But you could use C’s liburing directly for that if needed.
That’s serving 128 and 512 bytes so I suspect this server would then perform even better in that scenario. My benchmark was done serving a real 9.8 kilobytes index.html file. I’ll try to run it with 128 and 512 to see what I get.
Yes-yes, I understand. I mean you hardly will use such an approach (full HTTP-replies prepared in advance in RAM) for big files like video or so. And that is why I noted that it would be also interesting to utilize io_uring both for network and for file storage.
2 Likes
If I got it right, each thread at any moment of time is serving exactly one client.
But then there is no need to multiplex i/o (taking into account that you do not touch file storage at all). I/O multiplexing is for concurrency within single thread, isn’t it?..
When we want to serve many clients concurrently, we can
- serve one client by one process/thread (PG, for ex.) and let them block, concurrency will be arranged by OS.
- serve all clients in one thread using I/O multiplexing, no matter, reactor/proactor (redis for ex.)
- use several processes/threads (not many, one per CPU core or so) and serve many clients in each thread concurrently (nginx for ex.)
There is old text about C10K problem, just in case.
No, each thread can be serving many clients at once concurrently via its own io_uring. So it’s like taking your single threaded async model and multiplying it by the number of cores on the machine. The main thread is the dispatcher of accepted connections, sending them via the queue to the worker threads. The worker threads loop over both the io_uring completions and the queue from the main thread, so they can for example submit a first receive to one client and in the next iteration submit a send to another, and in the next receive again from the previous, etc. Whatever the kernel throws at them first or if something arrives at the queue.
I saw in a video about ew features in io_uring that there’s a new event type that lets you send messages directly between rings in the kernel. This would eliminate the need for the mutex protected queue between main thread and workers, possibly resulting in ever better performance. But Zig’s io_uring layer in std doesn’t have this yet.
4 Likes
Ah, ok, that’s the right architecture! I just did not realized this at first, sorry.
No worries my friend. I still have to test several other methods of handling the events. For example, would it be better to collect several operations (sends, receives, accepts) and then submit them all in batch versus submitting them individually immediately when they are ready to be processed?
I guess It depends on how your clients work, I mean:
- connect, send-request, get-reply, disconnect cyclically
- connect then send-request, get-reply cyclically, then disconnect
- do clients use http pipelining? this usually complicates things on the server side
1 Like
Looking at the code, I noted that Zig std does not support recv_multishot, recvmsg_multishot and read_multishot.
Yes, I actually was uncertain on whether to use liburing directly to have the latest features at hand, but finally stayed with what’s available in std whith hopes those updates will come sooner than later. As a sign of hope, accept_multishot is already there!