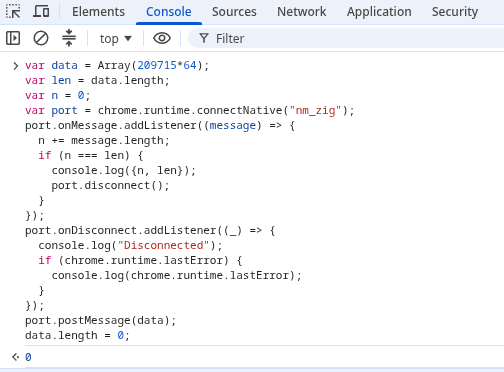
I posted the Zig version of a Native Messaging host here that users flagged and moderators removed due to the “generated” code being from Google Gemini.
I’ll try again.
This is the original, handwritten JavaScript (originally written and tested in QuickJS JavaScript engine/runtime) Native Messaging host that I have used online converters to port to Zig, Rust, Lua, Ruby and several other programming languages NativeMessagingHosts/nm_qjs_64.js at main · guest271314/NativeMessagingHosts · GitHub
#!/usr/bin/env -S /home/user/bin/qjs -m --std
// QuickJS Native Messaging host
// Original hand written 64 MiB parsing/processing implementation
// guest271314, 5-6-2022
function getMessage() {
const header = new Uint32Array(1);
std.in.read(header.buffer, 0, 4);
const output = new Uint8Array(header[0]);
const len = std.in.read(output.buffer, 0, output.length);
return output;
}
function sendMessage(message) {
if (message.length > 1024 ** 2) {
const json = message;
const data = new Array;
let fromIndex = 1024 ** 2 - 8;
let index = 0;
let i = 0;
do {
i = json.indexOf(44, fromIndex);
const arr = json.subarray(index, i);
data.push(arr);
index = i;
fromIndex += 1024 ** 2 - 8;
} while (fromIndex < json.length);
if (index < json.length) {
data.push(json.subarray(index));
}
for (let j = 0;j < data.length; j++) {
const start = data[j][0];
const end = data[j][data[j].length - 1];
if (start === 91 && end !== 44 && end !== 93) {
const x = new Uint8Array(data[j].length + 1);
for (let i2 = 0;i2 < data[j].length; i2++) {
x[i2] = data[j][i2];
}
x[x.length - 1] = 93;
data[j] = x;
}
if (start === 44 && end !== 93) {
const x = new Uint8Array(data[j].length + 1);
x[0] = 91;
for (let i2 = 1;i2 < data[j].length; i2++) {
x[i2] = data[j][i2];
}
x[x.length - 1] = 93;
data[j] = x;
}
if (start === 44 && end === 93) {
const x = new Uint8Array(data[j].length);
x[0] = 91;
for (let i2 = 1;i2 < data[j].length; i2++) {
x[i2] = data[j][i2];
}
data[j] = x;
}
}
for (let k = 0;k < data.length; k++) {
const arr = data[k];
const header = Uint32Array.from({
length: 4
}, (_, index2) => arr.length >> index2 * 8 & 255);
const output = new Uint8Array(header.length + arr.length);
output.set(header, 0);
output.set(arr, 4);
std.out.write(output.buffer, 0, output.length);
std.out.flush();
}
} else {
const header = Uint32Array.from({
length: 4
}, (_, index) => message.length >> index * 8 & 255);
const output = new Uint8Array(header.length + message.length);
output.set(header, 0);
output.set(message, 4);
std.out.write(output.buffer, 0, output.length);
std.out.flush();
}
}
function main() {
while (true) {
const message = getMessage();
sendMessage(message);
}
}
try {
main();
} catch (e) {
std.writeFile("err.txt", e.message);
std.exit(0);
}
Here’s the protocol
Chrome starts each native messaging host in a separate process and communicates with it using standard input (
stdin) and standard output (stdout). The same format is used to send messages in both directions; each message is serialized using JSON, UTF-8 encoded and is preceded with 32-bit message length in native byte order. The maximum size of a single message from the native messaging host is 1 MB, mainly to protect Chrome from misbehaving native applications. The maximum size of the message sent to the native messaging host is 64 MiB.
Note that the protocol currently uses JSON. That means that when processes the maximum a client can send to a host (64 MiB) only 1 MiB can be sent back to the client from the host per message. For simplicity and versatility I’m only dealing with JSON Arrays, which are closest to Uint8Array (u8), which can basically contain any kind of data, from live streaming audio and video to QUIC streams, etc.
Assuming I have only the experience of trying to port that JavaScript code to Zig using online converters, how would you go about porting the code to Zig for cross-target purposes?
I am a human asking other humans for help here. Thanks.