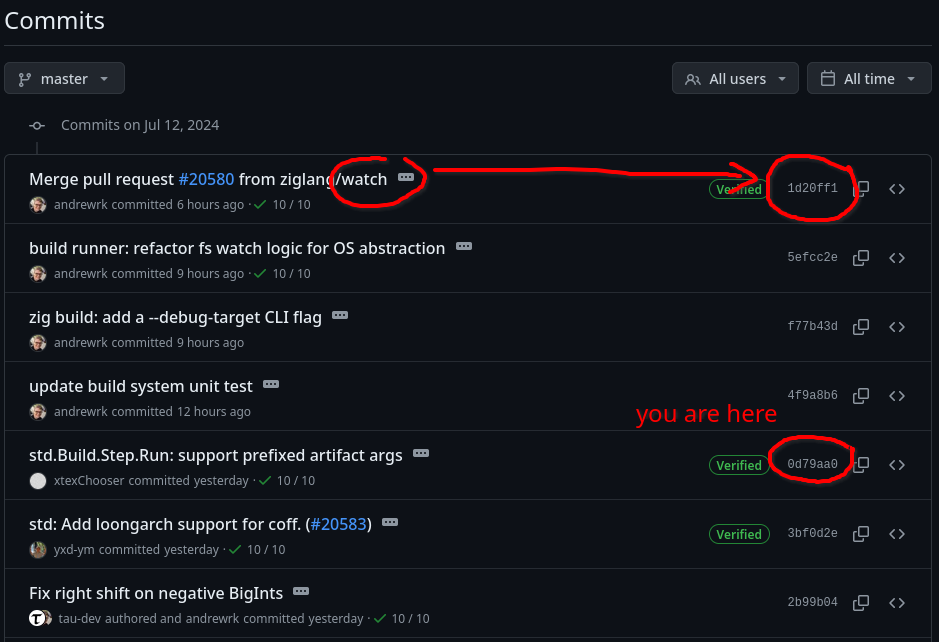
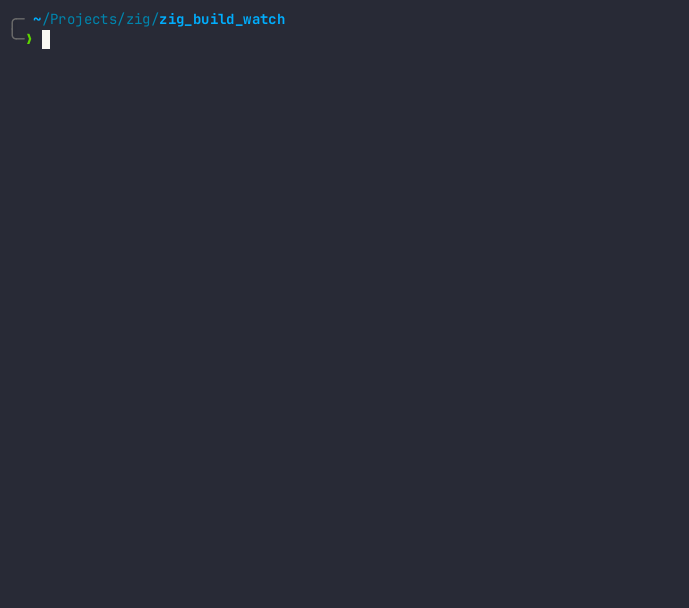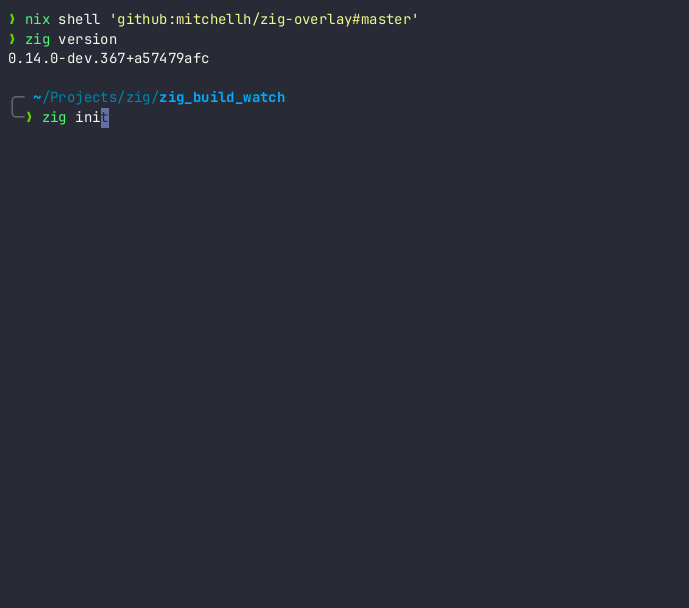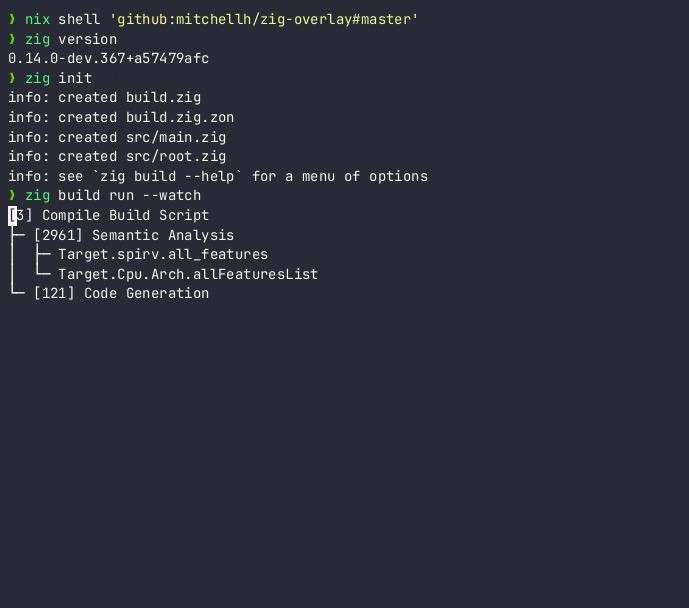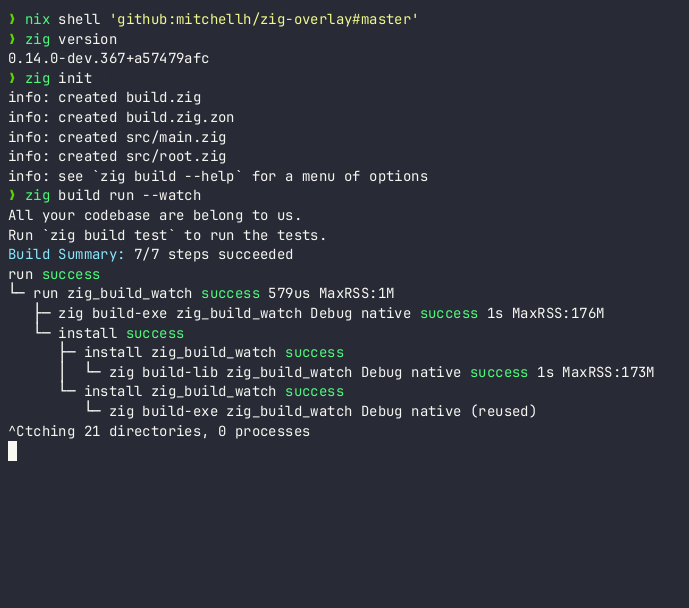
For those adventurous Zig users out there living on master branch, and who happen to use Linux, give the new --watch flag a try, and see if you like it.
Windows and macOS support are close, just needs some OS-specific glue code to make it work. I’m fairly confident the abstractions that I made will hold up nicely when it comes to those file system APIs since it’s based on watching directories only. Contributions welcome!
The way I see it, the end goal here is having incremental compilation + keeping the compiler alive for a long time for maximum compilation speed, and in that case keeping the rest of the build pipeline up-to-date is table stakes.
My recollection is that doing a bullet proof abstraction is quiet tricky here, as it’s easy to loose updates. If you read the file first, and then register a watch, then any updates in between the two events are lost. It might be useful to have an atomic “readAndWatch” primitive, or, after registering a watch, do a first freshness check even before you get a first update event.
I can’t say that I fully understand the current implementation, and maybe it does handle it correctly, but the loop in build_runner looks suspicious to me:
var w = try Watch.init();
rebuild: while (true) {
runStepNames();
// If file is updated here, will it be picked up?
try w.update(gpa, run.step_stack.keys());
try w.wait(gpa);
markFailedStepsDirty(gpa, run.step_stack.keys());
}
If I am reading the code correctly, update here takes a set of file paths. To avoid the races, it seems it should accept path together with hashes of the content actually observed by runStepName.
Not on the first build - same as how it won’t be picked up with a regular zig build if you edit source files while the build is running. However, once the watch is established, it will pick up changes that happen during rebuilds because the change notifications will queue up inside the fanotify buffer.
I haven’t looked at any of the code yet, but on the off-chance you’re not already aware of the many inotifiy gotchas it might be worth reading correct or inotify: pick one — wingolog.
Yeah looks like Linux didn’t future-proof their flags argument in name_to_handle_at, so that will need to be handled as an error instead of unreachable.
I don’t think anyone filed that bug on the issue tracker yet.
This is of topic, but, in general, watching directory recursively feels like an unsolved problem at this point. Luckily, it seems that zig doesn’t have to do this.
The fundamental problem is that you can’t treat “walk the directory recursively” and “watch the directory” as separate operations. That is inherently racy.
Though, I am skeptical that a hypothetical non-racy API could provide guarantees that wingolog wants. They seem to want to see the total order of modification events, but it’s not clear if that exists at all, especially for cases like networked file systems.
It seems some form of eventual consistency is more achievable:
the input to the API is a predicate, which describes which subtree of the file system is watched (it’s a predicate over all existing and future paths)
the output of the API is the stream of events, which gurantees that at least one event is delivered per path after that path becomes quiescent (importantly, this includes the initial even “this path exists” when registering a walkwatch).
This API requires some state full bookkeeping. And that stateful booking I think is an explanation for why watchman is a service, rather than a library: it essentially polyfills missing stateful OS APIs.
Now, as Zig doesn’t do recursive watching, I think that it dodges most of the complexity. Though, I am not sure how I feel about the races it does have. For the purpose of --watch flag during development, this is completely irrelevant. The thing is, no one is doing watching correctly, and that works absolutely fine at small scale, you only get to “gosh, I really need something like watchman” once you have giant monorepo, VCS, and production incremental build system that all want to process changes incrementally.
It does in some cases, for example if you add a directory to a WriteFile step:
You are right that if somebody adds a directory while the pipeline is being run, it may fail to acquire a watch mark.
I feel comfortable with this limitation. Even without file watching, there is already the existing limitation that editing a source file during the build pipeline may cause a problem, for example, if the file is read twice and expected to be the same both times.
To me the main concern here is whether this limitation interferes with the use case of using the build runner as a child process in an IDE, where users are expected to be editing files at any time, including potentially while the build is running.
I think this would be fine, but not ideal. Here, this=possibility of lost updates if some events happen in quick succession (eg, you add an @import, and then modify the imported file while the build is running, or some such).
Some things that happen in this situation:
Some editors write files frequently: there might be a very low auto-save delay.
git switch changes a bunch of files all at once (in general, switching branches is a good quick test for change-tracking and incremental)
Symlinks are in general hard to handle correctly, if you want to wach stuff.
Some changes are in-memory only. So there needs to be some code somewhere which merges the file-system view, and the in-memory view, and it also needs to handle the case where the source of truth for the document changes.
That’s some fiddly code, and a lot of bugs can hide between server-side file watching, client-side file watching, and reconciling the two, and the bugs are annoying to reproduce. Which is the main thing which makes me queasy about the possibility of lost updates: if you know that the low-level build always gives correct results (eventually), then any residual observed bugs must be on the editor’s side.
At the same time, if there are bugs, they are benign. It’s hard to get stuck with an inconsistent state, the user can almost always unbreak things by saving the file. Which makes the bugs into mere annoyances, but also makes them harder to fix (user work-around, rather than report issues)
This might have implications for incremental compilation. I guess the right term here is “repeatable read”? Depending on the implementation, it could be the case that a compilation reads the same file from disk twice, assumes that result is going to be the same, and something panics if that’s not the case. To avoid crashes, there either needs to be some sort of snapshot semantics, where the reads within a single compilation are repatable (eg, by only reading each file once), or otherwise the code should be prepared to not crash (its ok to return an error here and recompile from scratch)
Ah, I guess another interesting case here is cancelation (not sure whether there should be cancellation). If build is canceled mid-way, but caches some results, it must still watched the files touched.
i’ve been consistently calling zig build via entr for some time now and i have concluded that this is the way to go for me. having continuous support from the compiler, together with a couple of scripts to accelerate grepping and std navigation has proved me faster and more comfortable than the blotchy and unexpected nature of lsp ever did. hooray for one dependency getting goodbyed.