I think it is a bug. It’s documented that stream() can change r.seek and r.end as part of its contract. And then defaultReadVec() expects that r.end stays the same which I think is wrong. It should be either documented that readVec() expects this and needs to be overridden as well, or the defaultReadVec() should first store n = stream() before increasing the r.end.
Could you provide a reproduction? What you’re describing sounds more like illegal behavior/miscompilation. If you’re returning zero from r.vtable.stream, then r.end += 0 shouldn’t affect anything, and the const n = ...; r.end += n; change shouldn’t change anything about how the code works regardless.
It’s not always zero, it just only actually calls the underlying reader when it has exhausted it’s own buffer.
/// In addition to, or instead of writing to `w`, the implementation may
/// choose to store data in `buffer`, modifying `seek` and `end`
/// accordingly. Implementations are encouraged to take advantage of
/// this if it simplifies the logic.
I am opting to follow it this way, as opposed to using the writer. The buffer is large enough to contain the the maximum size of a fully decompressed chunk, so if the stream requests more than is available, it returns what is available to take, the caller updates the seek position automatically using the return value, and then would need to call stream again, but this time r.seek >= r.end, triggering for the next chunk to be read and decompressed into the buffer from the underlying reader. Rinse, repeat.
I am not 100% sure if what I am doing is idiomatic, but it does work in practice. If it is only by coincidence that it works, I am very open to any correction.
Right, I’m saying that this approach means that the function should always return 0.
With your implementation, if you use streamExact, it’ll hit integer overflow or return before n bytes are actually written. If you use streamRemaining, the return value will be larger than what was actually written to w. Etc.
test "Decompress indirect allocating" {
var in: std.Io.Reader = .fixed(test_data_compressed);
var aw: std.Io.Writer.Allocating = .init(std.testing.allocator);
defer aw.deinit();
var decompress_buf: [Decompress.recommended_buffer_size]u8 = undefined;
var decompress: Decompress = .init(&in, &decompress_buf);
const decompressed_len = try decompress.reader.streamRemaining(&aw.writer);
try std.testing.expectEqual(aw.written().len, decompressed_len);
}
With stream using return limit.minInt(r.end - r.seek);, this test will fail with something like expected 20, found 40.
One question though to help me understand why this works in my specific scenario: I am always decompressing a full chunk in one step, and the data in the underlying reader immediately following is the uncompressed header of the next chunk. This is why I included the assert(zlib.reader.seek == zlib.reader.end); to ensure that it fully consumed the available compressed portion of data. These compressed/uncompressed sizes are known ahead of time from the chunk header, which is not included in the example code.
Otherwise, if I were not doing this fully in one go using a buffer size that is guaranteed to be able to contain the whole data, then my mistake would have manifested in an error?
That is unrelated. If you’re not writing to w, you must always return 0, no matter what.
How you deal with buffer sizing is up to you. From here:
The implementation chooses:
What the minimum buffer capacity is asserted to be (perhaps zero)
Under what conditions an undersized buffer capacity can cause runtime failures (as opposed to assertions)
The implementation documents these things carefully, and asserts as early as possible.
My tentative advice for implementing a stream that always returns 0 would be:
At the beginning, if necessary, rebase to free up as much space in the buffer as needed (example from flate)
Refill the buffer as much as possible
Store any state necessary to continue from where you left off
Return 0
In your case, if you can’t guarantee that your buffer size is large enough to store an entire chunk’s worth of uncompressed data at-a-time, then you might need to store something like remaining_uncompressed_size and the flate.Decompress instance, i.e. the flate.Decompress/decompress_buffer would move into the SaveFileReader struct, or something along those lines.
(note that I’m in the early stages of writing an article about all this stuff, so my advice might end up changing)
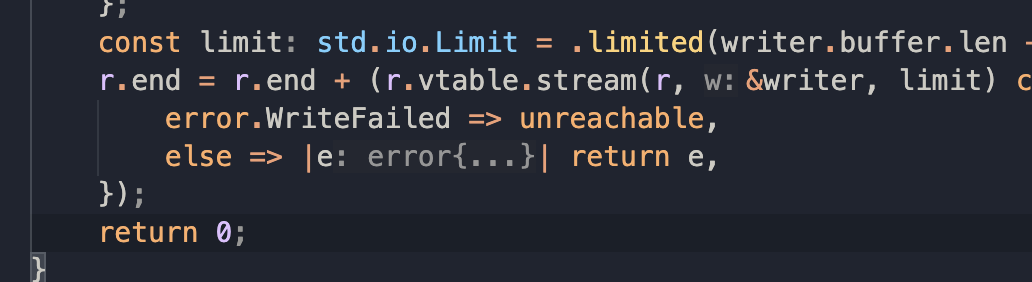
Yes, but it might take a while. Why do you think it’s a miscompilation? Isn’t r.end += stream(...) just a shorthand for r.end = r.end + stream(....)? Because that could be still wrong?
I can post the repro somewhere but it will take a while, I’m currently traveling and I’m not sure when I will have enough time. I could also just post you the whole curl.zig but I’m not sure if it would be useful by itself because the bug might be only observable if you call r.peekGreedy(r.buffered() + 1) which is what I’m doing in my SAX parser.
In Java terms, think of std.Io.Writer as an abstract class, where the abstract methods are defined in the VTable field. The rest of the class is defined in terms of the methods in the VTable. To implement a Writer, one only needs to implement these abstract methods, and the rest of the class will work by simply using these methods.
The use of the word “interface” for std.Io.Writer is correct, but confusing when coming from languages where that means something specific, like Java. “Interface” is used in the abstract sense in the context of Zig. Unlike Java interfaces, the Reader/Writer “interfaces” in Zig are stateful, and are largely concretely implemented in terms of their internal state, and the few methods (really only one is required, drain and stream for Writer and Reader respectively) that are left for the user to implement.
Yes I do return 0, but the problem could also be that r.end is re-assigned to its previous value (r.end = r.end + stream()), instead of just being incremented. I am not sure what += is really supposed to do and if it should be “atomic” or not - not in the concurrency sense but in the operation/operator sense → and what ASM it should generate. I could not find it in docs so I can’t be sure.