Thank you! Been looking for something like this.
1 Like
That’s true. The interface has functionality beyond just calling functions in the vtable.
It’s designed like that because buffering can be implemented in the same way for any type of reader or writer (files, sockets, etc). So the Io.Reader and Io.Writer add buffering for all these types, avoiding code duplication.
Because the interface struct in Zig is hand-crafted, it can do more than just forward calls to the vtable. However, if you want to draw a parallel to Java, you could consider that buffering implementation as similar to default interface methods in Java; sometimes they’re used to add functionality to a Java interface.
But keep in mind that Zig interfaces are not language constructs, they’re just an implementation approach using structs that can fill the same role as interfaces in other languages. There is no such thing as “an interface that is implemented by a type”, from the language point of view.
1 Like
Okay, so to highlight that point, and to put into a context I’m use to, would it be correct to say the std.Io.Writer is a concrete implementation that provides a mechanism to allow other structs to modify it’s behavior? i.e, I can’t just go implement my own version of std.Io.Writer and start passing it everywhere that expects the real thing. But I can modify it’s behavior by putting an std.Io.Writer interface on my struct and passing the buffer and the appropriate functions via the vtable?
I’m sure some of the language I’m using is slightly off, but that’s how I’m interpreting the conversation so far.
1 Like
Yes.
Let’s say you have a file-like thing and you want to provide access to it via Io.Reader/Writer. You could implement the vtable functions for your file-like thing, and then construct the Reader or Writer with your vtable. This gives you a common API and you also get buffering for free.
1 Like
I think I heard Andrew say in one of his talks that Zig would also be able to do this once this proposal was implemented.
And, if I understood correctly, that would mean the vtable would be optimized away entirely if there were only one implementation—just like you mentioned above with Java doing the same.
I’m a total noob and don’t understand half of what people are saying as this is my first foray into such a low level language, so take my comments with a grain of salt.
1 Like
Okay great, that helps a lot. I think I’m getting a much clearer picture now.
Thanks to everyone who replied, this was super helpful. I’m glad I found this forum, I’ll have to start looking through here more often.
I’m a total noob and don’t understand half of what people are saying as this is my first foray into such a low level language, so take my comments with a grain of salt.
Gotta start somewhere dude. We’re all learning ![]()
1 Like
Maybe it’s easier if you think it like this… java has inheritance, zig doesn’t. Where java would extend a class to inherit methods, zig must implement that ‘class’ as a nested struct. So types that want to implement Io.Reader and Io.Writer do that, in that interface field.
2 Likes
Removing the vtable to call functions directly (devirtualisation) is not exclusive to Java’s JIT, zig/llvm can and does do it and zig has accepted a proposal that should improve its ability to do so quite dramatically.
The difference is zig is compiled ahead of time so in the case where an interfaces’ implementation is chosen at runtime it has no knowledge of which one will be chosen so it can’t devirtualise.
Whereas the JIT happens at runtime so it can wait to see which is chosen and then devirtualise.
2 Likes
Sorry for being dumb here, but I still don’t get it - I thought that the whole point of passing Io around was about that it’s then trivial to do timeouts, cancelling, and IDK what else (because everything has to go through that and so anything is easy to intercept).
But the std.Io.Writer.Allocating does not need that, and therefore I wonder what would happen in case of cancellations? Suppose there are 2 tasks (asyncParallel), one does something and gets cancelled after 100ms, and one simply writes 1G of random bytes using the std.Io.Writer.Allocating. I would expect that part of Writer contract is to stop writing - but it can’t because it’s oblivious of the current *Io.
1 Like
*Io won’t magically cancel everything. Your code still needs to cooperate to be cancelable.
For example you provided you can always write std.Io.Writer.AllocatingButItCanBeCanceled which would accept *Io and check if it was canceled at every drain
Yeah, I understand that my code is not going to automagically become pre-emptively multi-tasked. But I thought that the whole point of Io was to make any io-like interaction obvious and interceptable.
Would you expect std.ArrayList(u8).append to be cancellation-aware? The general answer is no because you would want only “blocking” operations to be cancelable (locks, timers, I/O syscalls).
A Writer.Allocating is basically an arraylist of bytes.
The expectation is that the 1Gb write will have to complete. Note that checking for cancellation is not a free operation and you don’t want to pessify your entire program to make any micro operation cancel-aware.
2 Likes
Yes, and I’d expect writing to be cancellable - no matter if I’m writing to array list, or to a socket… Because in lots of cases I don’t even know that (in: *Writer). Ok, I won’t distract anymore, let’s just see how it works out in practice.
1 Like
Okey consider this example.
const std = @import("std");
fn writeJuliaPPMImage(writer: *std.Io.Writer, width: usize, height: usize) std.Io.Writer.Error!void {
try writer.print("P5\n{d} {d}\n255\n", .{ width, height });
const widthf: f32 = @floatFromInt(width);
const heightf: f32 = @floatFromInt(height);
const max_iter: u8 = 255;
const zoom: f32 = 1.5;
const c_re: f32 = -0.7;
const c_im: f32 = 0.27015;
for (0..height) |h| {
for (0..width) |w| {
const wf: f32 = @floatFromInt(w);
const hf: f32 = @floatFromInt(h);
const x0 = zoom * (2.0 * wf / widthf - 1.0);
const y0 = zoom * (2.0 * hf / heightf - 1.0);
var x = x0;
var y = y0;
var iter: u8 = 0;
while (x * x + y * y < 4.0 and iter < max_iter) : (iter += 1) {
const xtemp = x * x - y * y + c_re;
y = 2.0 * x * y + c_im;
x = xtemp;
}
const color: u8 = iter;
try writer.writeByte(color);
}
}
}
pub fn main() !void {
var buffer: [0x1000]u8 = undefined;
var stdout = std.fs.File.stdout().writer(&buffer);
const args = try std.process.argsAlloc(std.heap.page_allocator);
defer std.process.argsFree(std.heap.page_allocator, args);
if (args.len < 3) {
std.log.err("Provide width and height: \"/path/to/program width height\"", .{});
std.process.exit(1);
}
const width = try std.fmt.parseInt(u32, args[1], 10);
const height = try std.fmt.parseInt(u32, args[2], 10);
try writeJuliaPPMImage(&stdout.interface, width, height);
try stdout.interface.flush();
}
It creates nice image of a julia set.
$ zig run regular.zig -- 300 300 > out.ppm
But what if we pass 10000 10000 as parameters?
$ time ./regular 10000 10000 > out.ppm
real 0m9.446s
user 0m9.236s
sys 0m0.158s
(i zoomed in to show its high resolution)
It takes a lot of time so we want to limit it somehow. Here is my previously suggested WriterButItCanBeCanceled
const std = @import("std");
const CancelableWriter = struct {
writer: *std.Io.Writer,
canceled: std.atomic.Value(bool),
interface: std.Io.Writer,
pub fn init(writer: *std.Io.Writer, buffer: []u8) @This() {
return .{
.writer = writer,
.canceled = .init(false),
.interface = .{
.buffer = buffer,
.vtable = &.{
.drain = &drain,
},
},
};
}
fn drain(w: *std.Io.Writer, data: []const []const u8, splat: usize) std.Io.Writer.Error!usize {
var cw: *CancelableWriter = @fieldParentPtr("interface", w);
if (cw.canceled.load(.acquire)) {
return error.WriteFailed;
}
return try cw.writer.vtable.drain(cw.writer, data, splat);
}
pub fn cancel(w: *CancelableWriter) void {
w.canceled.store(true, .release);
}
pub fn cancelAfterSleep(w: *CancelableWriter, timeout: u64) void {
std.debug.print("start sleeping\n", .{});
std.Thread.sleep(timeout);
std.debug.print("wake up\n", .{});
w.cancel();
}
};
fn writeJuliaPPMImage(writer: *std.Io.Writer, width: usize, height: usize) std.Io.Writer.Error!void {
try writer.print("P5\n{d} {d}\n255\n", .{ width, height });
const widthf: f32 = @floatFromInt(width);
const heightf: f32 = @floatFromInt(height);
const max_iter: u8 = 255;
const zoom: f32 = 1.5;
const c_re: f32 = -0.7;
const c_im: f32 = 0.27015;
for (0..height) |h| {
for (0..width) |w| {
const wf: f32 = @floatFromInt(w);
const hf: f32 = @floatFromInt(h);
const x0 = zoom * (2.0 * wf / widthf - 1.0);
const y0 = zoom * (2.0 * hf / heightf - 1.0);
var x = x0;
var y = y0;
var iter: u8 = 0;
while (x * x + y * y < 4.0 and iter < max_iter) : (iter += 1) {
const xtemp = x * x - y * y + c_re;
y = 2.0 * x * y + c_im;
x = xtemp;
}
const color: u8 = iter;
try writer.writeByte(color);
}
}
}
pub fn main() !void {
var buffer: [0x1000]u8 = undefined;
var stdout = std.fs.File.stdout().writer(&buffer);
const args = try std.process.argsAlloc(std.heap.page_allocator);
defer std.process.argsFree(std.heap.page_allocator, args);
if (args.len < 3) {
std.log.err("Provide width and height: \"/path/to/program width height\"", .{});
std.process.exit(1);
}
const width = try std.fmt.parseInt(u32, args[1], 10);
const height = try std.fmt.parseInt(u32, args[2], 10);
var cancelable: CancelableWriter = .init(&stdout.interface, &.{});
const timeout = try std.Thread.spawn(.{}, CancelableWriter.cancelAfterSleep, .{ &cancelable, std.time.ns_per_s });
defer timeout.detach();
writeJuliaPPMImage(&cancelable.interface, width, height) catch {
if (cancelable.canceled.load(.acquire)) {
std.log.info("Write canceled", .{});
}
return;
};
std.log.info("finished writing", .{});
try stdout.interface.flush();
}
Notice how we use same blocking function but now it is cancelable.
$ ./cancelable 300 300 > out.ppm
start sleeping
info: finished writing
$ ./cancelable 10000 10000 > out.ppm
start sleeping
wake up
info: Write canceled
Obviously my implementation is not good. Correct one would just replace blocking sleep and writes with io.write and io.sleep
3 Likes
drain implementation in previous version was incorrect it never consumed data from buffer. So it would break if you provide buffer to it.
Here is correct version:
const std = @import("std");
const CancelableWriter = struct {
writer: *std.Io.Writer,
canceled: std.atomic.Value(bool),
interface: std.Io.Writer,
pub fn init(writer: *std.Io.Writer, buffer: []u8) @This() {
return .{
.writer = writer,
.canceled = .init(false),
.interface = .{
.buffer = buffer,
.vtable = &.{
.drain = &drain,
},
},
};
}
fn drain(w: *std.Io.Writer, data: []const []const u8, splat: usize) std.Io.Writer.Error!usize {
var cw: *CancelableWriter = @fieldParentPtr("interface", w);
if (cw.canceled.load(.acquire)) {
return error.WriteFailed;
}
const written = try cw.writer.writeSplatHeader(w.buffered(), data, splat);
return cw.interface.consume(written);
}
pub fn cancel(w: *CancelableWriter) void {
w.canceled.store(true, .release);
}
pub fn cancelAfterSleep(w: *CancelableWriter, timeout: u64) void {
std.debug.print("start sleeping\n", .{});
std.Thread.sleep(timeout);
std.debug.print("wake up\n", .{});
w.cancel();
}
};
fn writeJuliaPPMImage(writer: *std.Io.Writer, width: usize, height: usize) std.Io.Writer.Error!void {
try writer.print("P5\n{d} {d}\n255\n", .{ width, height });
const widthf: f32 = @floatFromInt(width);
const heightf: f32 = @floatFromInt(height);
const max_iter: u8 = 255;
const zoom: f32 = 1.5;
const c_re: f32 = -0.7;
const c_im: f32 = 0.27015;
for (0..height) |h| {
for (0..width) |w| {
const wf: f32 = @floatFromInt(w);
const hf: f32 = @floatFromInt(h);
const x0 = zoom * (2.0 * wf / widthf - 1.0);
const y0 = zoom * (2.0 * hf / heightf - 1.0);
var x = x0;
var y = y0;
var iter: u8 = 0;
while (x * x + y * y < 4.0 and iter < max_iter) : (iter += 1) {
const xtemp = x * x - y * y + c_re;
y = 2.0 * x * y + c_im;
x = xtemp;
}
const color: u8 = iter;
try writer.writeByte(color);
}
}
}
pub fn main() !void {
var stdout = std.fs.File.stdout().writer(&.{});
const args = try std.process.argsAlloc(std.heap.page_allocator);
defer std.process.argsFree(std.heap.page_allocator, args);
if (args.len < 3) {
std.log.err("Provide width and height: \"/path/to/program width height\"", .{});
std.process.exit(1);
}
const width = try std.fmt.parseInt(u32, args[1], 10);
const height = try std.fmt.parseInt(u32, args[2], 10);
var c_buffer: [0x1000]u8 = undefined;
var cancelable: CancelableWriter = .init(&stdout.interface, &c_buffer);
const timeout = try std.Thread.spawn(.{}, CancelableWriter.cancelAfterSleep, .{ &cancelable, std.time.ns_per_s });
defer timeout.detach();
writeJuliaPPMImage(&cancelable.interface, width, height) catch {
if (cancelable.canceled.load(.acquire)) {
std.log.info("Write canceled", .{});
}
return;
};
try cancelable.interface.flush();
std.log.info("finished writing", .{});
}
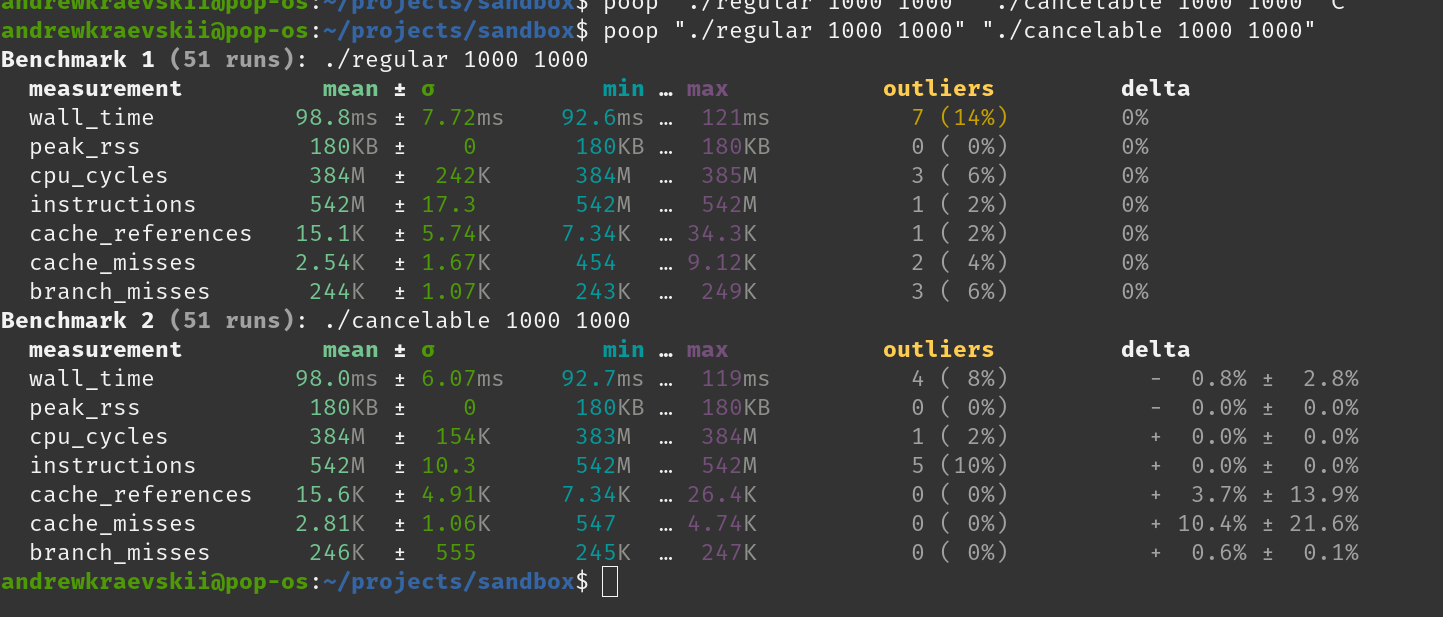
I moved buffer from stdout writer to CancelableWriter and now performance is not as bad (no virtual calls for every byte yay). Notice how I didn’t provide benchmark for cancelable version in previous post (it was really slow). And now there are no penalty for using it.
Here they both succeed:
Here second is timed out after 1 second:
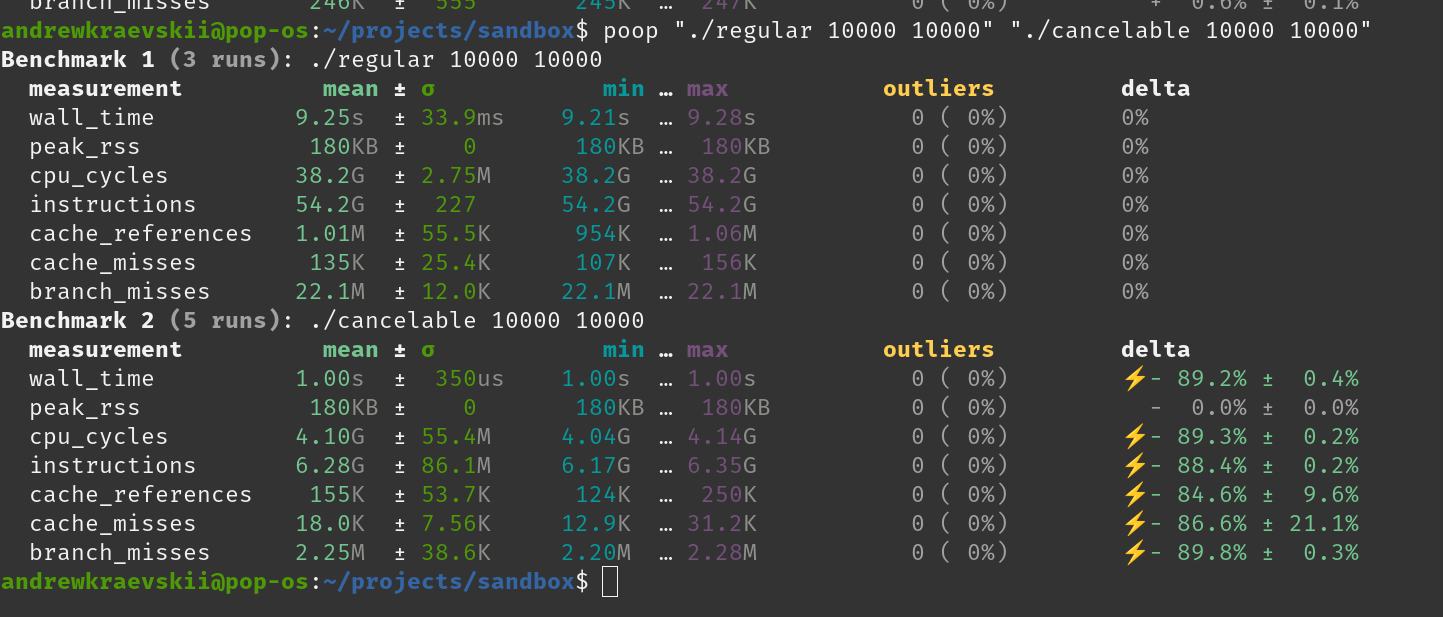
2 Likes
Thanks, that helped a lot
Been stuck on how to proceed porting some 0.14 code to 0.15 … where I have implemented a writer that wraps another writer, and applies some transforms on the data on the way through.
Your example above is perfect then - I just need to embed an interface field, and implement just the drain function. (and not forget to include the existing buffer contents before touching the data param)
If that’s correct, then it’s not half as much work as I thought I might be up for. Thx
1 Like
I was in a similar scenario, and had some data that was formatted into variable-sized chunks, where each chunk was an uncompresssed header followed by a Zlib compressed payload, which I wanted to implement a Reader for to make the process transparent to the user, and only stream the uncompressed payloads to.
Long story short, I spent much more time than I would have wished trying to understand the new reader/writer interfaces, but finally did have a “eureka” moment where it all just clicked in my brain. Since then, it feels simplistic and intuitive to do whatever I need, but I fully understand the struggle trying to initially wrap your head around it.
All that said, I still haven’t quite figured out the purpose of, or how to use/implement readVec properly, but I will cross that bridge when I come to it.
2 Likes
I am not sure, but I think I found a bug / doc issue.
Here’s docblock for vtable.stream()
/// In addition to, or instead of writing to `w`, the implementation may
/// choose to store data in `buffer`, modifying `seek` and `end`
/// accordingly. Implementations are encouraged to take advantage of
/// this if it simplifies the logic.
stream: *const fn (r: *Reader, w: *Writer, limit: Limit) StreamError!usize,
And then, there’s a defaultReadVec():
/// Writes to `Reader.buffer` or `data`, whichever has larger capacity.
pub fn defaultReadVec(r: *Reader, data: [][]u8) Error!usize {
...
r.end += r.vtable.stream(r, &writer, limit) catch |err| switch (err) {
error.WriteFailed => unreachable,
else => |e| return e,
};
return 0;
}
When I store the data in the r.buffer (and update r.seek & r.end) and return 0 in my stream(), it seems that the += is messing with my r.end. I hope I am wrong, but I have changed the code locally to const n = ...; r.end += n; and it fixed the issue.
NOTE: I’ve been hunting this for the whole day so it’s possible I have missed something but the fix seems to work.
This was one of exact points of pain that I also experienced. I was also making some incorrect assumptions about the purpose of the writer, but I digress. For the scenario that I mentioned above, this is what I came up with, which works:
/// Implementation of the `stream` function for transparently decompressing each chunk.
fn streamChunks(r: *std.Io.Reader, w: *std.Io.Writer, limit: std.Io.Limit) std.Io.Reader.StreamError!usize {
_ = w;
// Read and decompress the next chunk from the underlying stream if the buffer is empty
if (r.seek >= r.end) {
const save_reader: *SaveFileReader = @fieldParentPtr("interface", r);
// Read the uncompressed header directly from the child reader
const header = try readChunkHeader(save_reader.input);
// Create a child that is limited to only the compressed segment of the stream.
var limited_buffer: [4096]u8 = undefined;
var limited = std.Io.Reader.limited(save_reader.input, .limited(header.compressed_size), &limited_buffer);
// Wrap the limited reader into a Zlib stream and decompress into buffer
var decompress_buffer: [std.compress.flate.max_window_len]u8 = undefined;
var zlib = Decompress.init(&limited.interface, .zlib, &decompress_buffer);
try zlib.reader.readSliceAll(r.buffer[0..header.uncompressed_size]);
assert(zlib.reader.seek > 0);
assert(zlib.reader.seek == zlib.reader.end);
// Modify seek/end positions directly
r.seek = 0;
r.end = header.uncompressed_size;
}
return 0;
}
From what I can tell, the seek/update should only be modified manually if you are modifying the buffer of the reader in order to “redefine” what parts of it are valid. Other than that, the seek position will be updated automatically with whatever value you return from this function.
Ignore the use of the LimitedReader in this example, I am fairly sure that there is a better way to accomplish what I want, and possibly it is not even required, which i haven’t tested yet.
EDIT: Corrected the code according to below discussion.