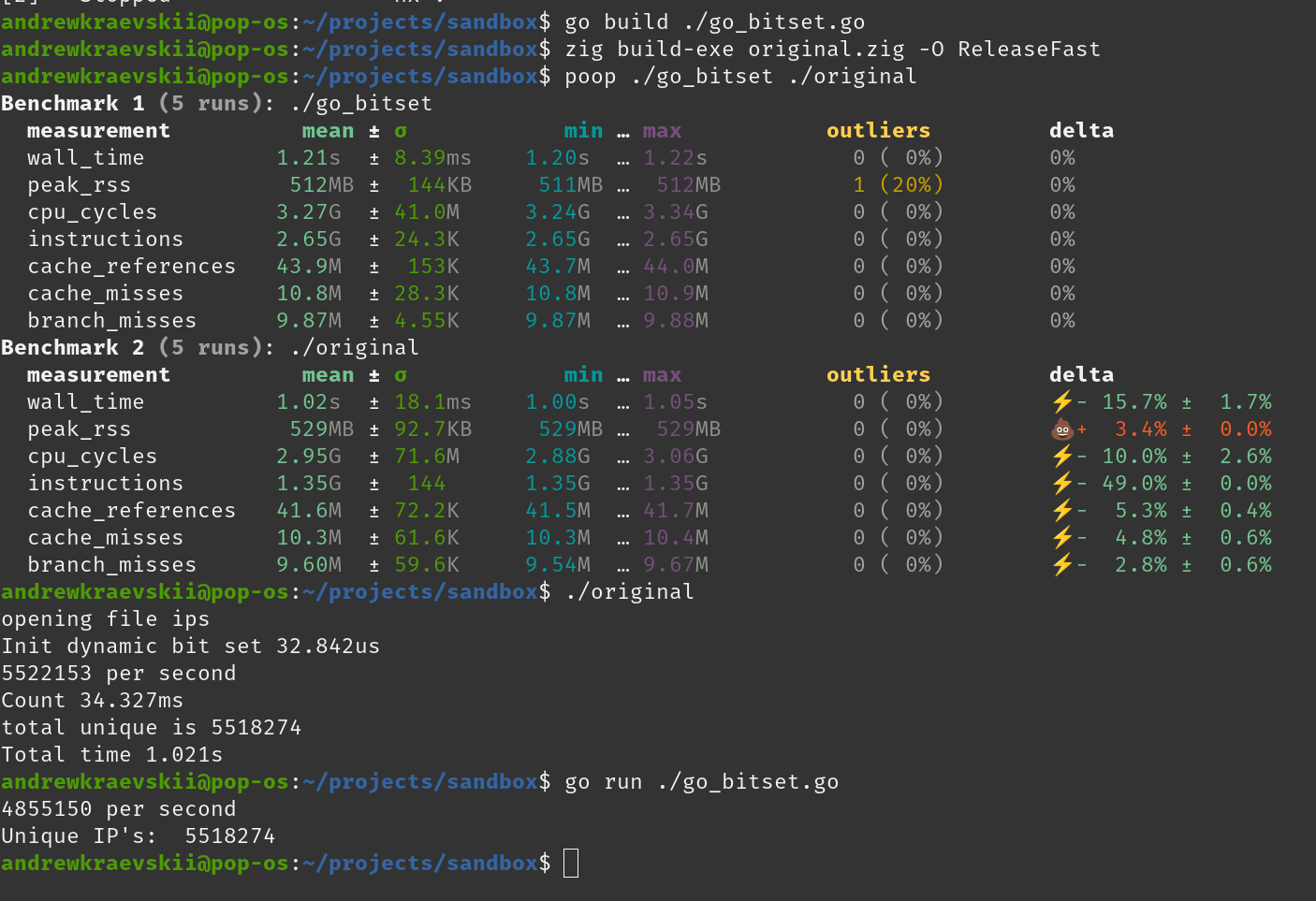
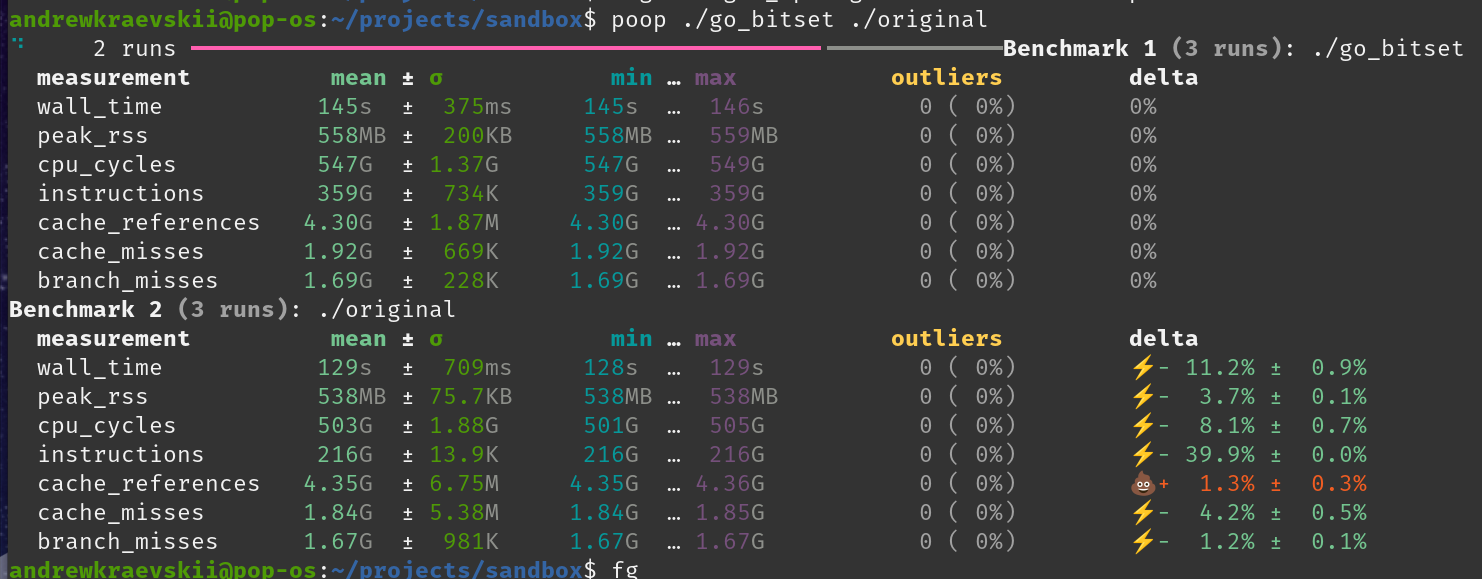
I have two programs one in Go and one in Zig. I believe the issue is in CPU intensive loop, but Zig cannot reach Go’s performance.
I think there’s a missing optimization in current Zig compiler? Release mode is on zig build --release=fast. Go version reaches 50M per second on my PC, but Zig 8M.
Here’s full Zig source code. I tried it with 0.15 and 0.16.0-dev.254+6dd0270a1 versions.
const std = @import("std");
pub fn main() !void {
const gpa = std.heap.smp_allocator;
var it = try std.process.argsWithAllocator(gpa);
_ = it.next();
const filename = it.next() orelse "small_set";
std.debug.print("opening file {s}\n", .{filename});
const file = try std.fs.cwd().openFile(filename, .{});
defer file.close();
var buf: [1 * 1024 * 1024]u8 = undefined;
var reader = file.readerStreaming(&buf);
var processed = std.atomic.Value(u32).init(0);
const thread = try std.Thread.spawn(.{}, printStatsLoop, .{&processed});
thread.detach();
var set = try std.bit_set.DynamicBitSet.initEmpty(gpa, std.math.maxInt(u32));
while (true) {
const line = reader.interface.takeDelimiterExclusive('\n') catch |err| switch (err) {
error.EndOfStream => break,
else => return err,
};
const num = parseIpV4(line);
set.set(num);
_ = processed.fetchAdd(1, .seq_cst);
}
std.debug.print("total unique is {d}\n", .{set.count()});
}
fn printStatsLoop(processed: *std.atomic.Value(u32)) void {
while (true) {
const first = processed.load(.seq_cst);
std.Thread.sleep(std.time.ns_per_s);
const after = processed.load(.seq_cst);
const per_second = after - first;
std.debug.print("{d} per second\n", .{per_second});
}
}
fn parseIpV4(line: []const u8) u32 {
var ip_buf: [4]u8 = .{ 0, 0, 0, 0 };
var ip_offset: usize = 0;
for (line) |char| {
switch (char) {
'.' => {
ip_offset += 1;
},
else => {
// profiler says this line is responsible for 70% of time
ip_buf[ip_offset] = ip_buf[ip_offset] * 10 + (char - '0');
},
}
}
return @bitCast(ip_buf);
}
I got this from linux perf record --call-graph dwarf

And this is Go implementation
package main
import (
"bufio"
"encoding/binary"
"fmt"
"log"
"math"
"os"
"sync/atomic"
"time"
"github.com/bits-and-blooms/bitset"
)
func main() {
fmt.Println("Unique IP's: ", UniqueIPs("small_set"))
}
func UniqueIPs(filePath string) int {
file, err := os.Open(filePath)
if err != nil {
log.Fatal(err)
}
defer file.Close()
bs := bitset.New(math.MaxUint32)
var processed atomic.Uint32
go statTask(&processed)
scanner := bufio.NewScanner(file)
scanner.Buffer(make([]byte, 16*1024*1024), 3*4+3+1+16) // 3*4 - numbers, 3 - dots, 1 - newline, 16 - just to be sure
for scanner.Scan() {
ip := parseIPv4(scanner.Bytes())
bs.Set(uint(ip))
processed.Add(1)
}
return int(bs.Count())
}
func statTask(processed *atomic.Uint32) {
for {
first := processed.Load()
time.Sleep(time.Second)
second := processed.Load()
perSec := second - first
fmt.Printf("%d per second\n", perSec)
}
}
func parseIPv4(input []byte) uint32 {
var ip [4]byte
var ipOffset int
for _, ch := range input {
switch ch {
case '.':
ipOffset += 1
default:
ip[ipOffset] = ip[ipOffset]*10 + (ch - '0')
}
}
return binary.BigEndian.Uint32(ip[:])
}
Example input data
97.71.173.241
97.71.173.235
161.71.174.27
215.10.61.107
161.71.174.29
227.215.10.99
161.71.174.30
215.10.61.63
161.71.174.31