Hello! I am pretty new to Zig and don’t really know what magic the compiler does under the hood. I am also bad at reading assembly.
I am playing around and benchmarking some sorting algorithms in Zig and I’ve stumbled upon something that confused me a lot. This is a C implementation of Selection sort, a toy O(n^2) algorithm:
#include "stdlib.h"
#include "stdio.h"
int main() {
int n = 20000;
int a[n];
for (int i = 0; i < n; i++) {
a[i] = rand();
}
int swap_count = 0;
for (int i = 0; i < n-1; i++) {
for (int j = i+1; j < n; j++) {
if (a[i] > a[j]) {
int tmp = a[i];
a[i] = a[j];
a[j] = tmp;
swap_count++;
}
}
}
printf("%d", swap_count);
}
This Zig code should hopefully be as close as possible to the C code:
const c = @cImport({
@cInclude("stdlib.h");
@cInclude("stdio.h");
});
pub fn main() void {
const n: i32 = 20000;
var ar: [n]i32 = undefined;
for (0..ar.len) |i| {
ar[i] = @intCast(c.rand());
}
var swap_count: c_int = 0;
for (0..n - 1) |i| {
for (i + 1..n) |j| {
if (ar[i] > ar[j]) {
var tmp: i32 = undefined;
tmp = ar[i];
ar[i] = ar[j];
ar[j] = tmp;
swap_count += 1;
}
}
}
_ = c.printf("%d", swap_count);
}
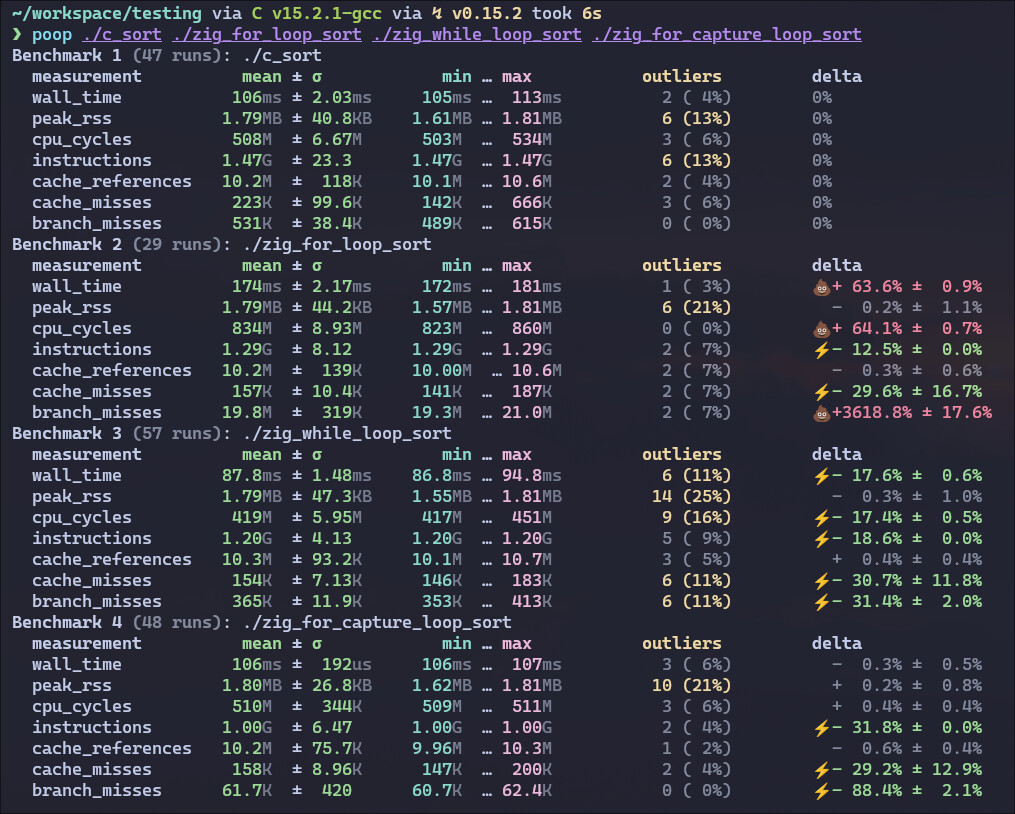
However, when I compile this with -lc -OReleaseFast, Zig is about 2x slower and does a huge amount of cache misses. It looks like some crazy unrolling. This gets way better for huge inputs like n = 1_000_000 and is basically equivalent in performance to C.
If I try compiling with -lc -OReleaseSmall, it’s faster and seems to match C assembly a bit more, but still underperforms C.
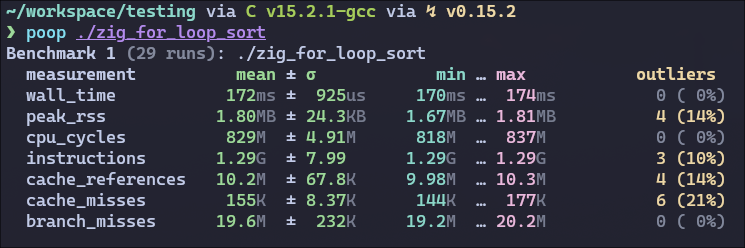
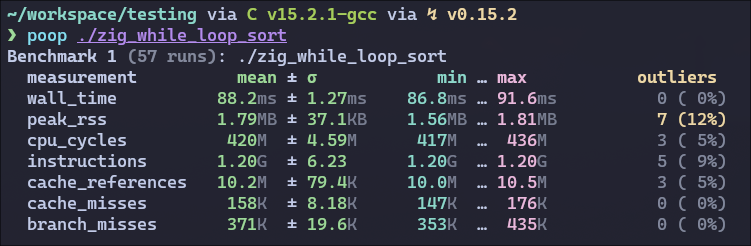
I tried compiling C with the flag -O3 using clang, gcc and zig cc, all giving me a better result than anything I’ve tried in Zig… However, when I try to swap around the for loops for while loops, Zig blows C out of the water with -OReleaseFast, but -OReleaseSmall is slower now. Only changing the inner loops seems to make a difference.
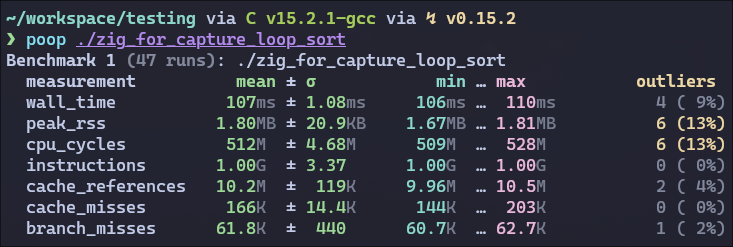
Also, when trying to use additional captures in the for loops for the elements themselves, I would expect it to be equivalent to indexing, but it is faster than the for loop version and slower than the while loop version and the branch miss count gets way lower.
Here are the benchmarks of the highest optimization settings:
I have many questions right now, but the main one is: Should I assume that my choice of loops will have an impact on the performance of my program?
I would have expected all of the Zig versions to be equivalent under the hood.
Hey welcome to the forum, I don’t know why you are seeing this difference, the only difference I see in your code is this part var tmp: i32 = undefined; but that shouldn’t change something meaningful, the difference between loops shouldn’t have a meaningful impact. Oh and I almost missed it, but in your C code you are using a VLA
after reviewing the godbolt, my best guess, is that the Zig code seems to unroll too aggressively, and because this is a comparison heavy code, the speculative execution must be constantly throwing and drained, which leads to slower code. I think you could probably reproduce that if you manually unrolled the C code, or hinted the compiler to unroll aggressively too.
Also if you wanted a fair comparison, you need to add -mtune=native on the C side, and when you do it does unroll like Zig. Still doesn’t fully explain why the for is faster than the while.
I’m away from my laptop, but I wonder if looping over slices and capturing pointers gives different results.
ETA: the following, while i guess technically less similar to C, feels more idiomatically Zig to me and i wonder whether it might give better performance.
const c = @cImport({
@cInclude("stdlib.h");
@cInclude("stdio.h");
});
pub fn main() void {
const n = 20000;
var ar: [n]i32 = undefined;
for (&ar) |*ptr| {
ptr.* = @intCast(c.rand());
}
var swap_count: c_int = 0;
for (&ar, 0..) |*p, i| {
for (ar[i+1..]) |*q| {
if (p.* > q.*) {
const tmp = p.*;
p.* = q.*;
q.* = tmp;
swap_count += 1;
}
}
}
_ = c.printf("%d", swap_count);
}
“the code doesn’t compile” is not helpful as a response. the missing ampersand compile error would have been fixable without me opening my laptop if i had gotten the error message as a response
zig and c are different languages and their compilers make different assumptions. i think it’s fair to ask to compare idiomatic C and idiomatic Zig in these situations.
Yeah sorry, I did but forgot to update the message ahha, but to be fair I don’t think ptr is idiomatic Zig code, the while loop with index would be what I would think has idiomatic zig code in this case
the output appears to be sorted in descending order rather than increasing, which suggests i made a typo?
oh, i see, i misunderstood the inner loop: it should instead be for (ar[i+1..])
sorry to complain twice in one thread, but again replying that the code produces “garbage output” suggested to me initially that there was a potential miscompilation when a little more diligence would have revealed that the numbers were sorted backwards.
I ran your fixed version (it correctly sorts ascending now) and there’s no difference in performance under ReleaseFast between your version and the original nested for-loop version
ahhh, ok that sounds to me like the compiler is eliding loads from p and/or q? idk if that would qualify as a compiler bug or if my solution is too cute.
I happened to check that. When the Zig -O ReleaseFast version uses while in the inner loop, it exactly matches the performance of the C version under clang -O3
Loop unroll optimization is notoriously finicky stuff, that suggests that tweaking some part of the later stages on the way to LLVM IR could get a better result.
Ok, I’m completely lost then. So, the question is how to find out, for example, how quickly this C function `ar[i] = @intCast(c.rand());` is called from Zig?
Nah, it’s just that by using rand() the data is the same in the Zig version, and the number of swaps are the same. c.printf is presumably just used because it’s already there and std isn’t used anywhere (and it doesn’t affect the result)
The perf difference is in how the loops are lowered by Zig (same result as the C version if inner loop is a while)