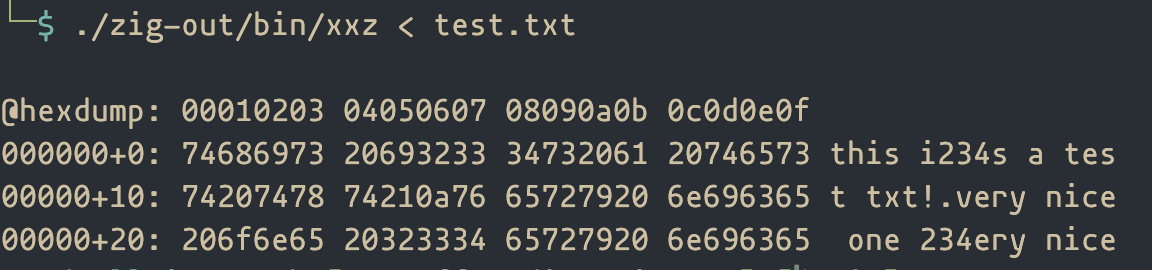
Hi guys, once again I want to thank people who helped me with my previous post, so just now i want to share what I’ve been working on: https://github.com/walltime1/xxz
I will be grateful for any feedback, and I am most interested in developing an understanding about writing really productive code and making this app ass fast as possible. Also I’d like to rewrite as much code as possible to comptime, but for now I really am not getting this topic at all.
That is WIP, I am looking for a way to drop reading from the stdin if a valid file can be read, either from -f or as a last parameter. Currently the stdin has the upper hand, because I haven’t managed to handle the case with it’s being empty.
In zig, operations that write to a buffer usually return a slice of the written portion (with the correct length, of course). Be mindful to use the slice, and not the buffer, to use the witten data.
Before I figure out slices I manages to find that readAtLeast returns N read bytes which fits my purpose, but for now I’m stuck with casting usize to u8. Any tips on that?
There are a slew of casting builtin functions, particularly around integers. Which you use would depend on the use case. Where are you getting a usize that you want to be a u8?
there is @truncate(), but that will be lossy if you have values > 255
An alternate approach is to not pass in the bufferLen value at all but just the slice. Slices contain both a pointer and a length. You would get something like this: