It’s been a little over two months since I’d even heard of Zig; and shortly I’ll be showcasing some fruits of my journey – many of which have been sweetened by the exceptional support and encouragement fostered by this forum ![]()
In anticipation, however, I’d like to first brainstorm about a rather novel approach to meta-programming I’ve come to embrace when developing software for resource-constrained MCUs – where every byte of memory and μJoule of energy matters.
SOME BACKGROUND
I’ve designed a programming language named EM back in 2010, which has seen use in a small number of very high-volume commercial applications using ultra-low-power wireless MCUs. A quick-read of the twenty Q & A’s found here should give you a sense of where I’m coming from and where I’d like to go towards making this technology openly and freely avaiable.
While my focus remains on developing MCU firmware that’s both higher-level in design and higher-performance in deployment, the burden of supporting EM as a general-purpose language for broad(er) use in the embedded space is a daunting effort – compared (say) with maintaining an internal, proprietary tool used by a handful of programmers.
Which brings us forward to Zig – a language that not only embodies many features I’ve already implemented in EM, but includes capabilities that I often wished I had in EM (but just didn’t have the time to develop). As they say: If you can’t beat’em, Zig•EM ![]()
FROM LANGUAGE TO FRAMEWORK
For the past two months, I’ve been working on a “proof-of-concept” in which the current EM programming language and runtime would effectively be grafted onto Zig. The net effect is that EM would be “downgraded” to a programming framework – but still targeting resource-constrained MCUs as before.
With a large base of legacy EM code in my software BAG (basement / attic / garage), I’m evolving a “re-write pattern” that I’m currently applying by hand to a (small) subset of this codebase featured in recent docs and blogs.
Said another way, each legacy EM source file (Uart.em, Timer.em, FFT.em, …) will morph into a corresponding Zig•EM file (Uart.em.zig, Timer.em.zig, …) that now relies upon the Zig compiler to produce MCU firmware.
Needless to say, I’m not forking Zig – creating my own divergent notation. By design, I’m using the language “as is” – embracing its capabilities while constraining myself to using Zig in its current form. (No rants about the choice of keywords, requirements for semicolons, curly braces around blocks, and so forth ![]() )
)
Beyond some syntactic differences on the surface, both EM and Zig are (obviously) Turing-complete languages at their core. The trick, however, is to “zigify” programming concepts and constructs central to the EM language, while remaining true to their original meaning and intent.
To cite just a few examples:
-
an EM
moduleorinterfaceis a language construct that would require a specific “usage pattern” to realize in Zig; -
the EM language has syntactically distinct primitives for toggling real-time debug pins (which I can emulate using Zig’s
@"..."identifiers for these special functions); and -
EM has a rather novel approach for turning
.emsource files into.outbinaries, which is certainly worthy of some brainstorming.
ZIG COMPTIME || EM CONFIGURATION
And now we come to the heart of this topic – just how far can we leverage Zig’s comptime meta-programming to realize EM’s novel build flow, in which each program is actually executed TWICE. Full disclosure – nothing’s been decided, and everything still matters!!!
There is an inherent asymmetry between the host computer and the target MCU when cross-compiling for a resource-constrained embedded system: the former has virtually unlimited MIPs and memory, a file-system, internet access, etc; the latter might have just ~16K of memory!!
Needless to say, ANYTHING that can be (pre-)computed at build-time relieves pressure on run-time resources. Details notwithstanding, Zig and EM are philosophically aligned and kindred spirits on this point.
For historical reasons, there have been no shortage of “configuration tools” in the embedded space which are invoked upstream from the cross-compiler itself – generating (C/C++) data-structures which encode hardware setup, scheduling policies, algorithm coefficients, etc. The “configuration language” is typically data-centric (XML, JSON) and often prepared using a GUI.
Long before conceiving EM, I was already using JavaScript as my configuration “meta-language” for writing complete programs that would compute and output statically-initialized data-structures (and sometimes small code fragments) consumed downstream during cross-compilation.
Even today, each .em source file is transpiled into a corresponding .js and .cpp file – with all of the former code aggregated into a JavaScript (meta-)program that executes on your host computer. See this blog post for a quick overview of the flow.
What’s novel, of course, is that EM is its own meta-language – and with the same sort of fluidity that Zig’s comptime affords. Said another way, one programming language serves as the linqua franca for two distinct programming domains – in my case, a resource-rich host computer and a resource-constrained target MCU.
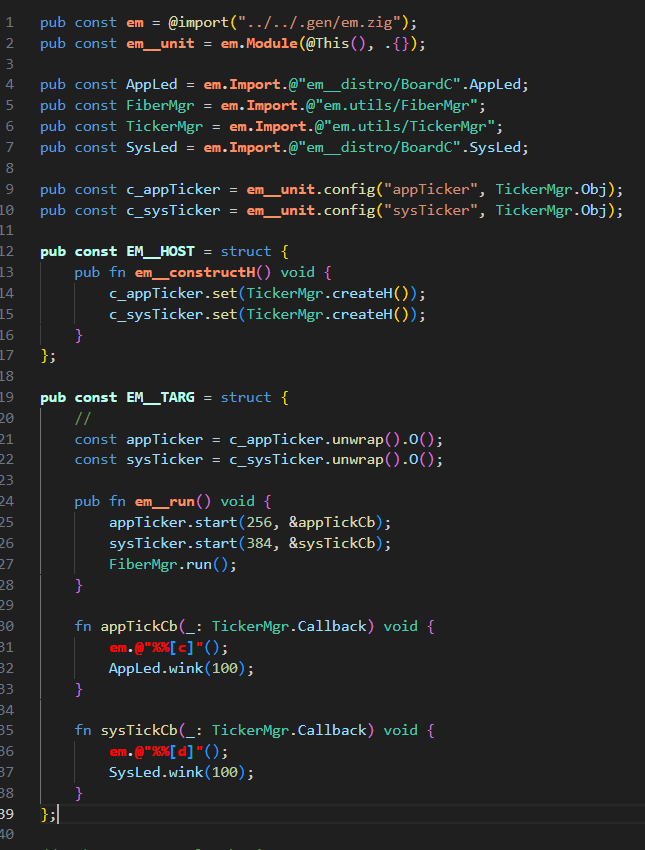
While I’ve already leveraged comptime in implementing the EM framework in Zig (and I continue to learn more everyday about what’s possible), I’ve perhaps taken a more conservative approach by funneling much of the application-specific meta-programming into a separate upstream meta-program – written in Zig, translated by the Zig compiler, and leveraging almost any library function in the Zig runtime.
With so many EM modules relying on application-level meta-programming for downstream configuration, having a “normal” program flow in which I can use print to trace my execution as well as read/write data files flattens the learning curve considerably. Leveraging some key features of the Zig language and compiler, partitioning a single .em.zig source file into elements that are either restricted to the host or target environment or else are common across both domains is actually quite expressive.
Whew!!! Let me stop here to get some feedback from y’all on whether this approach has merit, highlighting a rather novel way to use Zig in applications where the run-time domain is extremly limited in capability. Is this approach more powerful and expressive than comptime alone (elevating meta-programming to a complete meta-program)??? Or am I just being lazy ![]()