I haven’t worked a lot with libraries in zig, maybe two or three aside std.
Still, I found a common pattern between those library (not std): they tend to overuse anyerror or the global error set in general.
Often libararies’ APIs do not explicitly disclouse the error set, which I think is a vital information about whatever usage I will do of such library.
A bit out of context, I’m currently writing quite a bit of java for school and I see how exceptions and error handling can get out of hand pretty easily.
I find zig’s error handling is amazing and that it forces me to think a lot about which errors should be handled in place, bubbled-up or even just crash the program.
Here comes my thinking: zig forces me to aknowledge that some exception could happen, but doesn’t say how.
This information in zig is packed in the error’s name, which should be explicitly expressed in the function’s return error union.
I belive this breaks “Communicate intent precisly” and “Favor reading code over writing code.”
Thus, why not forcing explicit error unions and just erase anyerror all along?
This proposal comes from appreciation of the great use zig makes of friction.
I see why this could come along as annoying, but long term could be a good thing.
I also see why at the application level an explicit telling the return error union may not make sense, but I still see a way in which the whole ecosystem could benefit.
There is one use case for anyerror that I found and it’s storing errors of any type in type-erased container, that can be cast to a specific type in the typed container.
anyerror is one of those things should be avoided, but does have reason to exist.
The main use case being type erased errors, as @lalinsky mentioned.
I could see an argument to replace anyerror by just being generic over the error set if needed.
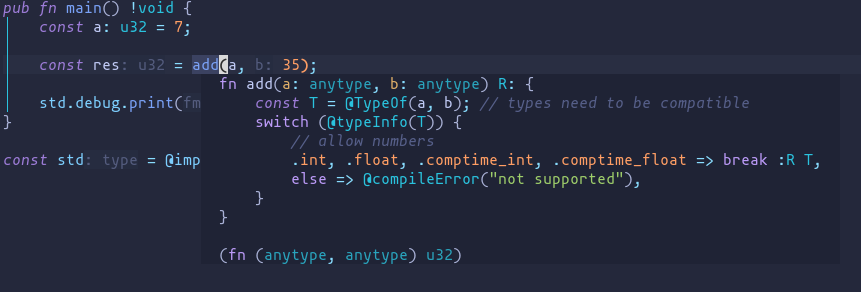
It’s more verbose, but zig claims it cares more about explicitness, I think the existence of anyerror and anytype contradicts that.
anyerror and anytype just don’t go along well with zig’s explicitness philosophy:
If a function allocates, takes an Allocator.
If a function does I/O, takes an Io.
Until here all fine, then comes anyerror: if a function can fail, it’s up to you to decide if the way it fails is meaningful for the user or not - and anytype: yeah just put whatever you want and we’ll play guess-the-param-type.
This is the kind of stuff that in big, complex systems leads to tribal knowledge.
Hence, seeing anyerror and / or anytype makes me wonder what their places are in such a precise and expressive language, and if there’s something better.
At the end of the day, excluded @lalinsky use-case, it’s mostly a matter of laziness.
Let’s take a database libarary as example with a query(T: type, query: []const u8, ...) !T.
Say I put this in a backend executable, which exposes some API endpoints.
I made an error in my query, the user makes a request, the query() call will just return a random error and bubble it up to main, which will result either in panic or a random 500: server failed error message to the client.
The point is: I need this information, and I shouldn’t be looking at your 1000 LOC to figure out what’s happening.
In place error recovery cannot be properly done without this knowledge.
Sure I could just retry the query, but can I really? What if it returns OOM? Does it return OOM? Or any hard error? RTFM? Too weak of a contract, I don’t want to rely on people being able and having the time or the will to write good documentation.
I really do believe there is a lot of value in this information and it should be more explicit, and makes me think to what extent one/two use-case out of a thousand possible use-cases justifies a footgun like this.
I agree with your point, but the situation you described does not exist, and the possible errors it returns are known at compile time. If you are failing to handle any of them, the compiler will give you an error and list which ones you are missing, similar a switch on an enum where you are not handling all its members.
That said, it is a poor practice to make consumers use compiler errors to figure out the error set instead of just defining it, though I can’t say that I have personally encountered such a situation, but I tend to only use the standard library and not rely on 3rd party packages due to the rapid development cycle of pre-1.0.
I think libraries that provide an API to use a database (and similar) should use an API with explicit error sets and if there is some need to have custom error values then they should have an extensibility mechanism that allows the library user to provide an error set that gets merged into their own explicit error set.
(I think inferred/implicit errors are fine, but using anyerror where it isn’t needed is bad)
I think there are valid usecases for anyerror, but if a library just uses it out of laziness instead of for valid reasons, than that should be reason to avoid that library, or fork it, or file an issue with it.
I think anytype is quite different and mostly just a more convienent way to write func(comptime T: type, val:T) and it is up to the library design to document and assert that some value of a valid type is provided.
Personally I don’t really find anytype problematic, just add a documentation comment for the parameter that explains what is expected so that I can read it directly from within my editor. And if that isn’t enough then going to the definition of the function should usually be enough to understand what to pass.
I wanted constraints on anytype in the past, but I am not really convinced anymore that they are really useful / necessary, I think just displaying anytype parameters better within editors would be enough.
Maybe there could be some doc-comment syntax that defines a descriptive constraint name that is used instead of only anytype (maybe displayed as anytype(Parser) within the editor), but the bad thing about constraints enforced in actual code is that it creates a whole new vocabulary that needs to be learned and is a reinvention of the equivalent zig code (which most of the time is easier to read and understand, than to remember new constraint names and helper functions which wrap this kind of constaint validation logic, so in the end I actually agree with just keeping anytype and reading the source code for the actual definition of whats allowed).
My point comes from zig making great use of friction in the right places to force devs to think and avoid certain patterns, generally leading to better code (IMHO).
That made me think about anyerror and the inferred error set (which aren’t the same think as I discovered 10 min ago lol) and if it should be allowed to do this.
Still I see that there are useful cases, but since friction is already being used I don’t see why it shouldn’t be enforced all the way through.
Btw: I read the anyerror and inferred error set langref, I see there’s a difference but am I getting this right? Is it that anyerror refers to the global error set, so it means that the function can return any error and the inferred error set just collects all possible errors that could arise from the function’s internal calls / operations?
Thanks to anyone who has the patience of explaining this to me!
I see your point, but shouldn’t there be only one way of doing things?
I find documentation to be a weak contract, and going to definition kind-of defies the point of “Communicate intent precisely”, doesn’t it? I think there is no better intent communication than hovering on a function / searching it in docs, looking at the returned error set/expected param and just say: “ah, this is what it returns/expects”.
What lead you to change you mind?
I like this idea, but I’m not sure it would entirely solve the problem.
Isn’t it kind of like putting a band-aid?
Hmm, maybe you could argue for replacing anytype with a typing/declaration system where comptime parameters can be implicit if they can be inferred.
One part that annoys me about Zig is when I repeatedly need to write MyTypeCalculatingFunction(@TypeOf(val)) for both the return type expression and the result variable within the function.
One thing I had considered is what if we had comptime variables associated with a function definition something like:
with {
const T = @TypeOf(val); // this is sort of tautological
const R = MyTypeCalculatingFunction(T);
} fn func(val:T) R {
var res: R = undefined;
for(std.meta.fields(R)) |f| @field(res, f.name) = .empty;
return res;
}
Or to avoid tautology have an infer keyword:
with {
const T = infer type;
const R = MyTypeCalculatingFunction(T);
} fn func(val:T) R {
var res: R = undefined;
for(std.meta.fields(R)) |f| @field(res, f.name) = .empty;
return res;
}
with would basically add a syntactic way to have comptime variables associated with a function, so that you can avoid repeating expressions.
Or without with:
fn func(val: infer T) MyTypeCalculatingFunction(T) {
const R = MyTypeCalculatingFunction(T);
var res: R = undefined;
for(std.meta.fields(R)) |f| @field(res, f.name) = .empty;
return res;
}
Having infer type variables could be an alternative to anytype, in this example it would be basically equivalent to this code:
fn func(val:anytype) MyTypeCalculatingFunction(@TypeOf(val)) {
const R = MyTypeCalculatingFunction(@TypeOf(val));
var res: R = undefined;
for(std.meta.fields(R)) |f| @field(res, f.name) = .empty;
return res;
}
I think some kind of infer would probably be nicer syntax, but it also may require more complexity in the compiler, not quite sure.
Regarding one way of doing things, I don’t think forcing the user to explicitly type the type every time is better (if that is what you mean), you already have the type of the thing when you write const my_value:u32 = 5 having to type it again when calling doSomething(u32, my_value) isn’t the same as being able to just call doSomething(my_value).
So said another way there is one way to call a function with explicit parameter types and one way to call a function that has implicit parameter type.
I think some kinds of implicit are good.
If everything was explicit you would have to type the type of the tuple value given to print/format functions and I think that would be horrible, also at that point the Zig language would feel more like writing an intermediary format.
But in the case of generic arguments that can accept different types there isn’t a compelling precise way to denote what is expected, all the ways I have seen to express a contract for generic arguments have been math-ish looking expressions that are defined in a parallel type-expression language which is simple to read for simple cases and almost in-decipherable for complex cases, with Zig we already can write comptime code to make calculations based on types and that seems better to me than having a separate dsl notation for expressing type constraints.
You then could put that code in a function and give it a name, but then you are back to learning a bunch of vocabulary for types classified/named in different ways.
I am not completely against being able to specify type constraining functions, but it has its own downsides (more complexity in the compiler, more vocabulary, potentially disallowing types that would have worked but are rejected because of rigid type checking logic, instead of embracing duck typing). And the issues that proposed similar things are closed, so it seems unlikely.
anytype is simple and you can write type checks where they are really necessary and use ducktyping anywhere else, if you use good names for your anytype parameter then that already explains what to pass in 90% of cases, for the rest 8% you can use documentation comments and pop open the detailed lsp-info for the function which shows you those documentation comments, for the last 2%, you can just pass something and let the compiler errors guide you, which is more likely correct and precise than any manually defined constraint-expression, which either would have to capture the type with excruciating detail (so people would resent having to create those descriptions) or would be subtly wrong for example by disallowing more types then necessary / over-generalizing.
Also technically you already can do something like concepts in Zig, which is similar to constraints but just using existing Zig code (and the benefit is that it doesn’t require learning another language, or set of names for concepts, or even combinators, or even thinking in functional combinator logic instead of just zig code), for example this just uses a block expression to define the result type and does some type checking alongside:
In combination with what I wrote in the previous section, I think it would be more like adding another lego brick into the picture that creates “Zig code itself is enough to describe type constraints / concepts”.
I think instead of trying to import the solutions from other languages (which usually is “invent a new language which can do most of what the actual language already can do but differently and likely slower”) we should embrace the strength of Zig, meta-programming? write Zig that runs at compile time, build-system? write Zig that runs at build-time…
I think it would be better to have a solution that is just a slight tweak on how things work and then have the solution fall out of that as a lucky find.
Basically having orthogonal features combine in ways that creates many possibilities, instead of creating too many overly specific solutions that don’t actually combine in a way that creates multiple benefits at the same time.
I have been toying with similar ideas for a while, one addition to this i think is really nice is being able to put the constraints in the with, which would just be normal zig code
with {
T: infer type, // yoinking the field/param syntax
// so you can use `const`s in your constraints
const T_info = @typeInfo(T).@"struct";
assert(T_info.is_tuple);
} fn foo(val: T) R {...}
Even the simpler case, that is just separating runtime and comptime args, IMO, would make zig so much nicer.
This also makes other generics nicer, and would be less wierd to those new to zig.
const ArrayList = with { T: type } struct {
\\...
};
Not sure how I feel about the calling side ArrayList{T}.empty, It can be confused with the normal literals.
Though, it also makes sense if you think about it as constructing the type, just like how you construct values.
Separation of comptime arguments constraints/definition is a very interesting concept.
Wouldn’t that be just a @typeOf under the hood? If not I don’t really understand what you mean with infer.
I didn’t mean forcing to explicitly tell the type ever time.
I think when functions are generic, then it should be explicit, like for example most of std.mem.
But as you said, there is the problem/risk of:
And on that I 100% agree, but I’d love to explore a way of being a bit more expressive on how that anytype argument should behave, like the concept of with and infer.
I think too that the solution lies within zig, and not a parallel DSL, because as you said:
This is very powerful, and (funny enough) something I have never seen in the languages I used.
I didn’t know one could do this in zig, amazing!
But why shouldn’t I just pass in the type for args, comptime check if the type “walks and talks like a duck” and avoid anytype all along? Wouldn’t this enforce some better design decisions and expressiveness?
Because we can do duck typing also without anytype, right? Or are there problems that can be solved only with anytype?
I also see that explicitly passing the type around may not solve the problem entirely.
Still your answer made me understand better the value of anytype, and while it’s (maybe) possible to find a “better” alternative, it’s still a indispensable element of the language.
I don’t think the same applies to anyerror, for which I think the points made remain valid.
IMHO, this is better separation of concerns, better intent communication and better readability.
Plus with LSP/hover functionality, one could right away see what type constraints the function expects.
I think it depends a bit on how infer was implemented if it was just a syntactical different way to write anytype, then it doesn’t seem like a meaningful change to me, but if it allowed these type variables and code running to determine the types used in a function declaration that seems, like it could come with downsides for being able to quickly process function declarations (which currently should be able to handle anytype just as a placeholder for a type which gets filled in later), that is why I say I am not sure, would have to study the current implementation and how it would need to change.
I think we are mixing two things here, one part is whether to use anytype or an explicitly passed type, the other is whether you ducktype or write type checks/use-constraints.
So you are right that you can pass the type explicitly and use ducktyping (however it is unusual for the dynamic languages where the term originated), it is just that I don’t always want to pass the type explicitly, for example if I would rather write it at the result location.
But ducktyping is when you don’t check, when you check you are building your own adhoc constraint checker and if you write it too constraining it will disallow some ducks, because they look or sound to much like geese , or even further with duck typing it is fine if a bear wants to behave like a duck and use an api that way.
I think checking/constraining vs ducktyping is a tradeoff between enforcing things and allowing things, so I don’t think there is a clear objective better way, until you specify the context where it becomes the better solution.
I am not aware of somebody proposing a construct like with, but I might have missed it, but I also don’t really feel like my thoughts about this topic are formed enough to feel confident about proposing it, at the moment it is more a thought of hey maybe there is something towards this direction/line-of-thinking, so that is why I decided to talk about it and your and @vulpesx’s responses have helped in thinking a bit more about it.
Here’s my favorite layout for handling generics in more complex cases (interdependent signatures, several functions etc) -
Make a function that takes types (and perhaps other comptime only arguments) and returns a no-fields struct type. Let’s call this a ‘voidspace’, because any instance would have the same binary layout as void, its purpose is be be a namespace, and it sounds pretty cool.
In the ‘voidspace’, construct all the derivative types and other comptime values you’re going to need, as const decls.
In the ‘voidspace’, define all the functions you want, with all the verbosity overhead eliminated by the const decls you just made.
If required, expose user-facing module-level (i.e. not in the voidspace) functions as thin (likely inline) wrappers that figure out how to construct the right voidspace and dispatch to one of its functions.
Adapting Sze’s example:
fn V(T: type) type {
return struct {
const R = MyTypeCalculatingFunction(T);
fn vfunc(val: T) R {
var res: R = undefined;
for(std.meta.fields(R)) |f| @field(res, f.name) = .empty;
return res;
}
};
}
fn v(val: anytype) type { return V(@TypeOf(val)); } // not sure if this better than repeating the @TypeOf below
inline fn func(val: anytype) v(val).R {
return v(val).vfunc(val);
}
In this case, it’s definitely more verbose, but it is still efficient in the sense that it doesn’t linger in the anytype zone, and in my experience it scales really well when you add functions and derivative comptime values.
Pedantic, but if a concept can be described with less than a medium sentence, then it’s not worth creating a new term.
Especially so if that new term is not well thought out.
‘voidspace’ is a terrible term for what can easily be described as a ‘generic namespace’.
Also, IMO, the wrappers are unnecessary, if you don’t want to type V(T), then make an alias for it. Outside of long and difficult to type names, I think not using an alias is more readable.
Brilliant use cases. What is the attitude of the core members of zig towards this usage? Is it worthwhile to promote it in the standard library? Some standard library function parameters are indeed difficult to understand, such as the Context parameter of HashMapUnmanaged. I’ve tried to express its constraints here using this style:
Well… its length is indeed somewhat… subtle. Indeed, when the constraints are a bit complex, readability suffers somewhat.
However, I think this might just be due to a lack of encapsulation. If the type checking of whether the Context pattern includes the pattern function could be encapsulated in std.meta, the code here could become much lighter.