Upgrading a fairly large project right now, and the productivity of -watch -fincremental is incredible. Fix error, save, jump to error, repeat until done.
5 Likes
I just finished porting my “from stream” CSV parser to 0.15.1.
It is somewhat basic implementation, but with the new Zig (on my old machine) it sped up by 14% and reached 550.2 million characters/s parse speed (including data validation and some after parsing data printing).
This sounds nice, but i encountered some surprising behavior in terms of cache misses.
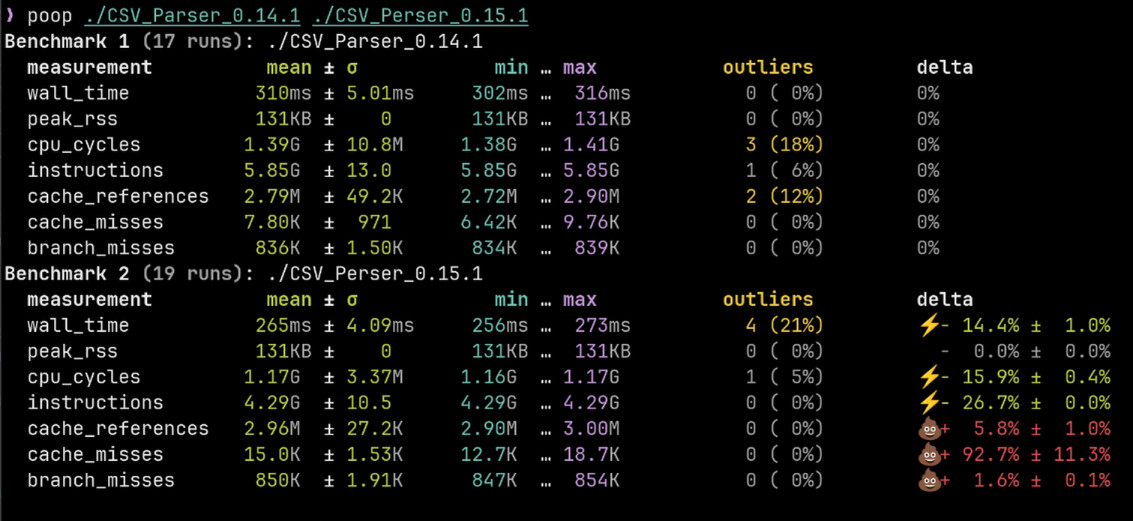
While the performance improved, executable size grew almost 2x.

The old implementation used BufferedReader() and directly called its read method. I have basically build my own readSliceShort() around it, so i just exchanged it with the one from new interface.
New one uses readVec() as its backing read method, but that should not change much. I also do some single Byte reading, which might not play nice?
Anyway, found this interesting and wanted to drop it here. Will do more digging once i return from work. If anyone has ideas what could be causing this, i would love to hear them.
Robert ![]()
EDIT:
When doing more runs, speed up is consistent around -14%, branch misses are consistently around +5% (its not a random deviation) and cache misses are reaching up to +130%.
5 Likes
One gotcha that was easy to miss while updating the code is that the new File.Writer defaults to keeping its own internal position for where to write, my old code used try handle.seekFromEnd(0) so that the old writer would append to the end of the file, after changing to the new writer that writer started at the beginning of the file instead (I guess I could change the mode to streaming (for example via file.writerStreaming()) to get the old behavior?), so I removed the seekFromEnd and instead initialized the write position on the file-writer this way: try writer.seekTo(try writer.file.getEndPos());
Currently it is a bit unclear to me whether it would be better to use positional or streaming mode for occasionally appending to a file in a single threaded way. Maybe some experimentation could show what is better. It seems the main benefit of positional is when you have some concurrency and accessing different parts of the file to write to them instead of just the end.
1 Like
The difference is really only important when you have multiple readers/writers to a single file,
streaming uses the position from the file resource, so it’s shared between all readers/writers of that file.
Positional, they each track their own position.
And ofc some kinds of files like stdio only work with streaming.
There are also *_reading modes which avoid the send file optimisation if you care about that.
1 Like
Positional also has the advantage that seeking is “free” in the sense that you don’t have to make any syscalls.
3 Likes
Congratulation on the release! It’s a huge milestone. I especially like the non-generic Reader/Writer.
I’m migrating my projects. I’ll report any issues as I work through the changes.
One change I have issue with is the deprecation of ArrayList.Managed. It basically pushes the memory management work to the users of ArrayList, which is the unmanaged version. Now I need to pass an allocator along whenever I pass an ArrayList as a parameter.
Edit: Just migrated TopoSort. Took about a hour. Basically migrated all the ArrayList usages. I ended up maintaining the allocator in my object and passed the allocator along.
2 Likes
That is one of the reasons for the change, it’s more explicit, and encourages you to allocate upfront if possible then use the AssumeCapacity or Bounded functions.
This is also acting on 0.14 deprecating the managed versions, there was plenty of warning, and the managed versions still exist so you can update with minimal change, though they will be removed in the future.
1 Like
Same, I wonder if it could also work for @typeName().
Also, now that there’s a specifier for everything I was looking for a bool one, but I guess it’s the only thing that doesn’t need one.
Noticed a couple langref inconsistencies:
The master version has links to version 0.12.0 (works) and 0.15.0 (broken) while all of the tagged versions have links to 0.12.1 and 0.15.1, instead.
Thought I’d point this out since https://ziglang.org links to the langref’s master version.
3 Likes
Wait, have only the ArrayLists’ unmanaged versions been made the default? So like, HashMaps’ default is still the managed versions – that’s a bit confusing.
7 Likes
There is something going on with ZLS.
Starting vscode I saw the message:
Failed to install ZLS 0.15.0: Not Found (404)
They had an issue, but should be fixed (at least for me in Neovim): zls compiling version checking doesnt identify 0.15.0 being further than 0.15.0-dev · Issue #2454 · zigtools/zls · GitHub
1 Like
It is installed now. But something (in the deep dark forest of options) is broken ![]()
1 Like
Another beautiful release <3.
Just finished migrating my bigger project, GatorCAT. Another performance datapoint:
Release workflow (zig build ci-test):
- Cross-compile from linux release-safe binaries for windows, linux
- build and run a zig script that calls system docker to build an image (like Tigerbeetle)
- build and run all tests
- build linux debug binary
Zig 0.14.1: 2m1.894s
Zig 0.15.1: 1m24.822s
![]() 30% faster!!!
30% faster!!!
Note: ran twice with deleted
.zig-cache(to avoid one-time effects of zig global cache state)
Debug workflow (faster iterations) (zig build):
- build linux debug binary
- make small change (print debugging)
Zig 0.14.1: 0m8.878s
Zig 0.15.1: 0m2.268s
![]() 74% faster!!!
74% faster!!!
Notes for future me if wanting to reproduce
zig 0.14.1 result is from git tag v0.3.10
zig 0.15.1 result is from git tag v0.3.11
7 Likes