I think simplest way forward would be to take a look at the data with renderdoc and figure out whether the vertex data is screwed up somehow.
1 Like
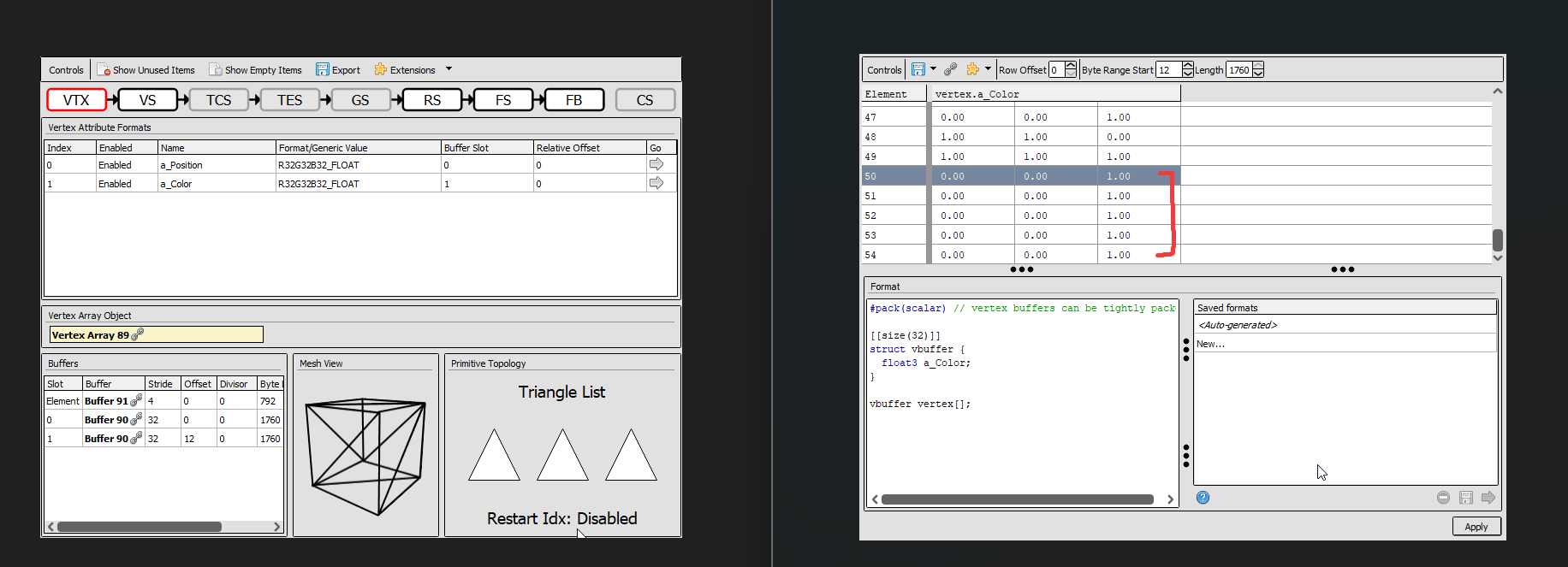
The correct colors seem to be stored, and nothing seems out of the ordinary (unless I’m not looking in the right spot).
You have the managed data structures in StorageList as static variables. That means that only one list will exist for a given type T no matter how many instances of StorageList(T) there are. This seems counter to the API you have designed, and is probably just wrong (I have only briefly read through the implementation). Maybe you intend to only have one instance of StorageList(T) per type T, but there are better ways to organize that.
1 Like
I intend to allow for multiple lists of the same type T to exist.
Could you elaborate on this? I don’t know if I’m understanding correctly.
I have the list as a static variable because I do not want the field to be accessible to the user as they might accidentally call a function directly to the internal list (as opposed to the wrapped functions) and break the wrapper.
I guess the Zig term would be container level variable.
That is not what container level variables are for, and private members like that are somewhat anti-zig (thus why they aren’t easily supported in the language). Just switch them to member variables and make the API clear.
Edit: link was wrong, now fixed
2 Likes
Thank you! I was not aware of that behavior, it seems static variables were a gap in my programming knowledge.
2 Likes
The StorageList and MultiStorageList fixes didn’t seem to change any behavior unfortunately, but I do have more information about it now.
I wanted to test when it would stop respecting the color data input, and it seems like it only listens to the very first set of .color.
For example:
_ = try renderer.newObject(
allocator,
&[_]renderer.Vertex{
.{ .position = .{ -0.5, 0, 0.5 }, .color = .{ 0, 0, 1 }, .tex_coord = .{ 0, 0 } },
.{ .position = .{ -0.5, 0, -0.5 }, .color = .{ 0, 0, 1 }, .tex_coord = .{ 0, 0 } },
.{ .position = .{ 0.5, 0, -0.5 }, .color = .{ 0, 0, 1 }, .tex_coord = .{ 0, 0 } },
.{ .position = .{ 0.5, 0, 0.5 }, .color = .{ 0, 0, 1 }, .tex_coord = .{ 0, 0 } },
.{ .position = .{ 0.0, 0.8, 0 }, .color = .{ 0, 0, 1 }, .tex_coord = .{ 0, 0 } },
},
&[_]usize{
0, 1, 2,
0, 2, 3,
0, 1, 4,
1, 2, 4,
2, 3, 4,
3, 0, 4
},
.{ 0, 0, 0 },
.{ 0, 0, 0 },
);
_ = try renderer.newObject(
allocator,
&[_]renderer.Vertex{
.{ .position = .{ -0.5, 0, 0.5 }, .color = .{ 1, 0, 0 }, .tex_coord = .{ 0, 0 } },
.{ .position = .{ -0.5, 0, -0.5 }, .color = .{ 0, 1, 0 }, .tex_coord = .{ 0, 0 } },
.{ .position = .{ 0.5, 0, -0.5 }, .color = .{ 0, 0, 1 }, .tex_coord = .{ 0, 0 } },
.{ .position = .{ 0.5, 0, 0.5 }, .color = .{ 1, 1, 0 }, .tex_coord = .{ 0, 0 } },
.{ .position = .{ 0.0, 0.8, 0 }, .color = .{ 1, 1, 1 }, .tex_coord = .{ 0, 0 } },
},
&[_]usize{
0, 1, 2,
0, 2, 3,
0, 1, 4,
1, 2, 4,
2, 3, 4,
3, 0, 4
},
.{ 0, 1, 0 },
.{ 0, 0, 0 },
);

Hopefully this sparks some ideas, as I’m still clueless.
I think
gl.DrawElements(gl.TRIANGLES, @intCast(object.index_count), gl.UNSIGNED_INT, object.index_start * @sizeOf(usize));
Actually makes sense because you append all the different objects to one shared buffer, at the time where I said to use 0, I didn’t realize that that was what you are doing.
1 Like
I probably could have explained that better. At least the colors are working now, and we’re back to the first 2 problems.
What data structure is vertices and indices?
vertices is a MultiStorageList and indices is a StorageList
pub var vertices: utilities.MultiStorageList(Vertex) = .{};
pub var indices: utilities.StorageList(usize) = .{};
pub const Vertex = struct {
pub const Index = enum(usize) { _ };
position: [3]f32,
color: [3]f32,
tex_coord: [2]f32,
};
My suspicion is that there is a bug in these implementations (apart from the container level variables problem, from what you have described about what you are seeing), I think it would make sense to try to replace it with a simpler data structure (for testing purposes) temporarily.
I think you basically could replace it with a big enough array that is initialized with tombstone values instead and remove also sets the tombstone value, iteration would then just continue on tombstone values. (Efficiency is not the point here just having a simple data structure to compare against)
Also have you written any unit tests for these data structures?
If not I think it would make sense to write some.
But I am too tired, taking a nap now, maybe I wake up with a good idea…
1 Like
I did a lot of testing before switching all of my struct data over to them. It took me a bit to nail down the remove() function and its quirks. As mentioned in initial post, I really do not think it is the data structure, as I printed out everything (each object in the list, and various prints inside of functions like updateBuffers()) with every output seeming very normal. I’ll do some more testing tomorrow just to make sure.
By the way, if you know of any other promising data structures, please share! I’m not set on this exact one yet. I’m just opting for something that I understand and will make things easier for me until it becomes a problem again. Realistically I just needed something with constant indices and easy iteration of active elements, which is why I chose the sparse set data structure.
I haven’t tried to use a sparse set on vertex data so from a practical standpoint I don’t know how it works out, however from my intuition it seems to me like it is too fine grained, I think I would instead want something that works more chunk based, or based on unique objects which are then moved around in memory.
I don’t think using constant indices is a hard requirement for something like this, I think it is very unlikely that all the geometry will be edited all the time, thus you will have a lot geometry that doesn’t change and that can just stay in a part of a buffer that is compacted and remains unchanging, while other objects get moved around to the other end of the buffer where objects have a bunch of free capacity between another and when that runs out, they are moved to increase their capacity to have more vertices for that object, while simultaneously adjusting their range of vertices.
I think if you pick a few good granular sizes for amounts of vertices based on what amount of vertices your objects typically have, then the whole finding a big enough bucket thing could potentially become quite simple. Yes you would potentially build up fragmentation over time, but I think having a simple incremental compaction step that moves a few elements is quite likely enough and should average out to a constant overhead.
That also would give you vertex data that is completely densely packed and ordered, I think that would help with synchronizing the data to the gpu via gl.BufferSubData and also would make it easier to manage change detection on larger chunks of data instead of single verticies.
Basically I think vertex data doesn’t need that many degrees of freedom, I think the only case where such a fine grained approach makes sense would be for something like sand simulations or something like that and even there I would expect more grouping.
My questions would be:
- What sort of editing of the vertex data do you expect to do?
- How many vertices and objects are involved in these operations?
- What percentage of your overall vertex data is that?
- What is your reason for wanting constant indices, does that really buy you enough for what you are sacrificing for it?
I think it is likely that being able to copy large chunks of data to the gpu is your most important operation, because it is unlikely that you want to iterate over and edit all your geometry at the same time and even if you wanted that, then it probably would make more sense to figure out a way to make your gpu do the editing transformations, then optimizing editing on the cpu and having a bottleneck of getting it to the gpu.
But yeah these are things to think about and there definitely could be things I am wrong about, I am also playing around with these things and still have to run more experiments and get more practical experience to find out whether my theoretical ideas match reality.
1 Like
After a bit of thought, I’ve come to realize the same thing. I don’t think I should be using the sparse set implementation on such low-level engine data like vertices, as I’m not working on a simulator or anything (I doubt I’d need to edit individual vertices to that extent anyway). I appreciate all of your help.
1 Like
Absolutely not. If running this stuff down in OpenGL is difficult, running it down in Vulkan would border on impossible. And I say this as someone who is currently writing lots of Vulkan in Zig. (At some point, I need to write a Vulkan tutorial “Vulkan for those who hate 3D”. Vulkan is remarkably useful for lots of 2D stuff but it all gets buried under the 3D documentation.)
And, as much as it pains me, I would suggest never using a wrapper for this kind of thing (either for OpenGL or Vulkan). Zig makes accessing the underlying C API completely straightforward and that’s what the vast majority of people use. You will have to file bugs and ask questions of people involved in those projects and those people are using C and C++. Zig accessing the C API is pretty readable to them even if a touch weird.
By contrast, any “wrapper” simply doesn’t have enough people to kick the bugs out of it. You’re going to wind up debugging the wrapper (mostly) and the underlying API. And a Zig wrapper around the C API will not be anywhere near as readable to the people you need help from.
Finally, while writing a game engine is a perfectly fine thing to do, I always make sure to ask whether people are trying to “write a game” or “learn 3D graphics” or “write a game engine”. These are very different tasks.
If they want to write a game, I point them at an actual game toolkit and see if that gets them moving. Motivation is a scarce commodity, and getting something/anything up and running fast is way better for that.
If they want to learn 3D graphics, I try to point them to OpenGL stuff, ShaderToy, 3D toolkits, etc. The goal here is putting triangles to the screen somehow and letting them incrementally build up their understanding.
If they want to “write a game engine” I try to discourage it. The people who genuinely need to “write a game engine” don’t even need to ask the question. They already know 3D graphics development cold, understand asset management in minute detail, and have very clear ideas as how to handle OS integration with events, sound, etc. They’re writing a “game engine” precisely because they know all the game engines and understand their failure modes. When that doesn’t hold, you wind up with Rust–where there are far more “game engines” than actual games written using those “game engines.”
2 Likes
I believe he was talking about how Vulkan is much more verbose than OpenGL, rather than it being easier or more complex.
I appreciate your insight, and I will take your message as a warning. I only plan to make this engine so I can teach myself a lot in the process (both a good portion of 3d graphics and the actual engine itself), as I know what ways of learning work best for me.
I don’t think further discussion on this topic is relevant enough to the original post, so I’ll end the conversation here.
That’s part of it. It’s explicit about everything. All the concepts map really well with hardware, so understanding the basics of the hardware will give you a pretty good understanding of what is possible and what is undefined behavior in Vulkan. In other words, undefined behavior in Vulkan makes sense, while in OpenGL it’s just arbitrary rules that exist simply because that’s how they were implemented.
And, most importantly, the excelent validation layers will almost always point you right where you’re doing something wrong.
I decided to learn Vulkan because I was writing a program in OpenGL and it simply would not do what I wanted. I tried everything, read the spec and all. When I wrote it in Vulkan, the validation layers pointed exactly where I was invoking undefined behavior. After giving it some thought, using Vulkan concepts, I quickly realized why it was undefined. It wasn’t arbitrary, it was related to GPU limitations. With that understanding, it was easy to find an extension that allowed me to do what I wanted.
2 Likes