and at the callsite you’d be able to put any expression expr that would be eligible for assignment like this
const arr: [_]ConcreteType = expr
It seems natural enough, but I understand that a certain line has been drawn at function calls, with good reason. Extra language complexity is the last thing I’d want to see. I wonder, though, whether inline fn would be able to be more permissive… it seems like it’s a fundamentally different sort of boundary than an ordinary function call, and might be allowed to accept as signature any type expression that would be allowed inline?
Doesn’t this require s be comptime-known? Admittedly, in my examples this was the case, but you could imagine passing a runtime value to the splat. It’s why I ruled out slices earlier - they can’t have comptime-known length without being entirely comptime-known.
I think it is fine to just use array: anytype and do some comptime type checking on that parameter in the function.
Sure some people tend to dislike anytype, but that is a whole other general issue, separate from whether the parameter is an array type or some other type, so I don’t think this topic has a more specific answer that applies to arrays specifically.
Because Zig doesn’t allow to define type constraints for parameter types, you have to either be more verbose and construct the type from multiple other parameters or use anytype and write type checking logic for that parameter yourself.
There are also a bunch of people who have used the return type expression to do that type checking, to basically create a userspace type checking library, however I don’t like how these libraries tend to replicate normal Zig type checking code by turning it into equivalent but unknown vocabulary that needs to be learned and thus creating additional burden for the reader.
I think it is better to use just normal Zig code with maybe a local helper, that is self describing through its name, so that the type-check is readable without any prior knowledge of an additional type checking library.
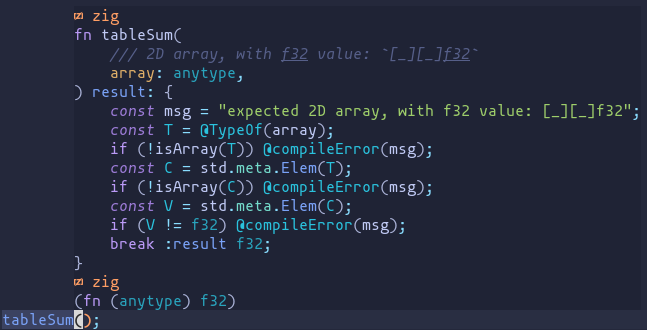
If you really care about the type of the parameter being described in something that shows up in for example Zls you can do something like this:
fn tableSum(
/// 2D array, with f32 value: `[_][_]f32`
array: anytype,
) result: {
const msg = "expected 2D array, with f32 value: [_][_]f32";
const T = @TypeOf(array);
if (!isArray(T)) @compileError(msg);
const C = std.meta.Elem(T);
if (!isArray(C)) @compileError(msg);
const V = std.meta.Elem(C);
if (V != f32) @compileError(msg);
break :result f32;
} {
var sum: f32 = 0;
for (&array) |inner| {
inline for (inner) |value| sum += value;
}
return sum;
}
fn isArray(T: type) bool {
return switch (@typeInfo(T)) {
.array => true,
else => false,
};
}
Which shows up like this when writing:
And like this when you vim.lsp.buf.hover it (I imagine that other editors show it similarly considering it seems to be a Zls feature):
There is no way where you can just use .{} (which isn’t an array literal btw), instead you can use a normal array literal specifying the types explicitly:
Personally I think this may actually be a good thing, because it makes it immediately obvious what the actual data passed to tableSum is and what the result of the @splats look like.
If you didn’t have to explicitly type it, you would first need to know how tableSum works / is defined. (If there was a way to make it work without specifying the type at the callsite)
It is also what the standard library does (using explicit array literals):
The answer to the topic question is, yes, pass it an array or array-literal.
The answer to the actual question:
Can I pass array expressions with inferred types and inferred length to this function?
is no, instead you have to specify the array type manually, because the function signature doesn’t contain enough information, to infer the type (even if complicated deep code analysis could figure it out (which Zig doesn’t want to do)).
inline fn propogates comptimeness of arguments, this allows you to express that an argument is only partially comptime, which you cant do with a non inline function.
only s.len is required to be comptime. However on further thought i think that code is incorrect, as it might, and probably does, require that s.ptr is also comptime, which is no different from fn(comptime s: []const T)
One thing I do want to point out from earlier in this thread is comptime s: []const T does not require the contents of the slice to be comptime known, only the length and the pointer, think of it as a struct with those fields, comptime does not propagate through pointers. However, you can have a pointer to a comptime only type which is a different situation (which I think is bugged atm).
Thanks, you two. I appreciate the time you’re putting into this very much.
@Sze , I agree with your point that it’s clearer if you put the length of the splats adjacent to them in code, and that what I’m trying to do is not actually that desirable an outcome. It just helps me understand things if I push up hard against the boundaries of what they allow.
@vulpesx , it had occurred to me that the values of a comptime slice might possibly be runtime known, but what does it mean at runtime? Would our splats actually write to some static memory location far away from the current stack frame? In any case, it hadn’t occurred to me that we could have a partially comptime slice, although of course it makes sense given that we can for structs. Thanks!
This I know! I was wondering about runtime-only values specifically. For some reason, I found it strange to think of writing to a static memory location located away from the current stack frame, which now that I’m saying it, is obviously not weird at all and I feel a little silly.
I tried this out, and unfortunately it doesn’t seem to work. I haven’t been able to create a slice with comptime known len but that isn’t entirely comptime known.
const std = @import(“std”);
pub fn main() void {
var v: u8 = 123;
const x: []const [3]u8 = &.{ @splat(v), @splat(3) };
const len = comptime x.len;
std.debug.print("{}", .{ len });
v += 1;
}
It works if you replace the v in @splat(v) with a comptime known value, but otherwise it’s giving me the unable to evaluate comptime expression error.
That would make the error go away, but it’s not the point. The theory is that one should be able construct a slice with comptime-known len but that is actually not entirely comptime-known.
With structs you can’t create runtime instances of them if some of the fields are comptime-only types (you get a compile error) (I am meaning normal fields here, not meaning fields declared as comptime field:type = value, because I see those as a special construct that only looks field like, but isn’t quite a normal field).
I don’t think Zig intends to support partially comptime fields for normal fields, would also make it awkward because you could have many combinations based on what happens to be comptime in a specific context.
It is much simpler to only deal with instances that are either completely comptime, or completely runtime (for example by comptime values being copied into runtime mutable memory).
For example I don’t know how you would get a pointer to the struct when it has 2 of its fields being comptime in one place and 5 being comptime in another. Or am I misunderstanding something? I think instead the struct instance either exists as a comptime value or as runtime value, but not some partial value in between the two.
It also seems to me like having such a boolean comptime/runtime way of dealing with instances would make it easier to implement incremental compilation correctly, but I don’t know for sure.
All that said, I don’t know if there is actually documentation that spells this out explicitly, so that is mostly my guesses.
I am not talking about comptime only types, I am talking about comptime known values (of runtime types), I am not surprised it’s as simple as it is, I had just assumed otherwise.
I do think there is an argument for being able to track fields values being comptime known or not, but that would obviously be more complex, both for the compiler and the programmer.
I am mostly looking for what decision andrew/the team have made or to get them to make it if they haven’t, I don’t particularly care which way they go, It’s just an ambiguity that I haven’t found a resolution to.
For me a comptime known value is one that can be used with @compileLog where it doesn’t print [runtime Value].
But I think there are values that print as [runtime Value], where the optimizer still is later able to discover something about them, or even completely eliminate them.
I think there can be quite a big difference between what is known at comptime and what is known by later optimization steps in the compiler, so while some things may not be comptime known, they are compiler known.
With this program:
pub fn main() !void {
var array: [10]u32 = @splat(0);
const len = 5;
@compileLog(len);
comptime var comptime_slice: []u32 = undefined;
comptime comptime_slice.len = len;
@compileLog("comptime_slice", comptime_slice.ptr, comptime_slice.len);
const final = comptime_slice;
@compileLog("final", final.ptr, final.len);
var slice: []u32 = final;
slice.ptr = &array;
@compileLog("slice", slice.ptr, slice.len);
}
I can’t figure out a way to make the slice.len non-runtime.
You can make the final.len comptime, the optimizer might even see later that len is a constant, but the slice.len isn’t comptime known from code running at comptime.
Where here there is practically no code left:
I think ultimately we need some more insight from somebody working on the compiler and probably also be more verbose about what we actually mean.
As you can see, in generic functions, T is actually as redundant as n, as you might think. This is done to express parameter constraints more efficiently in function signatures and improve readability.
If you’re not interested in this redundant expression to enforce function signature constraints, use anytype.
Perhaps you’re actually looking for something like interfaces to eliminate redundancy while still expressing constraints in function signatures. That would require new keywords, which Zig hasn’t yet decided on (and may never design). A crude keyword design might result in a code that only satisfies certain constraints without redundancy, but still introduces redundancy under more complex constraints, potentially leading to technical debt.
That’s okay, my point is that this level of redundancy is widespread in zig’s use of generics, including in the standard library.
For now, accept redundant generics, or choose to eliminate redundant anytype (although many people do not like this solution where constraints cannot be seen in the function signature, it does eliminate redundancy to the greatest extent)
The content about interface is just some personal discussion. I personally have no specific attitude on whether such functions should be added.
When it comes to type inference, my personal style is to confine it as much as possible. I would generally provide a low-level API with verbose signatures and no type inference, and a high-level API which is just a thin type-inference layer over the low-level API, likely using anytype and inline fn, to get rid of the verbosity in the most common use cases.