About Flux provides a broadly equivalent feature set to C++20 Ranges, but uses a slightly different iteration model based around cursors rather than iterators . Flux cursors are a generalisation of array indices , whereas STL iterators are a generalisation of array pointers .
From back here, it looks like a fairly modern C++ code base. They’re implementing some sensible defaults - max returns optional instead of throwing. They’re also taking an interesting stance by being index based instead of iterator based.
What you’d like me to specifically comment on? I’ve never been a fan of the C++ build system but that’s not really the fault of the library authors. Looks like they’re getting good AVX instructions generated as well. Looks like a fairly solid library.
Well, first, thanks for the question. I’ve gone back and fourth on the benefits of both ideas and I have a few thoughts I can share here.
First, Zig and C++ are entirely different animals. I write C++ professionally in my day job and the transition to Zig was… well… interesting. If I was writing this in C++, I’d be more tempted to go down that road for a variety of reasons.
An extremely important thing to consider here is the presence of two major components to the C++ ecosystem - destructors and hidden allocations. These definitely influence the mental model around lifetimes and stability.
I’m not a fan of destructors. IMO, it’s like someone took a garbage collector and split it into a thousand little autonomous pieces, lol. I don’t like to complain, but they just aren’t my style.
And operator new creates a lot of issues surrounding the stability of pointers. In Zig, it’s hard to ignore the fact that you’re allocating. Also, lifetimes are thought about more in terms of allocators and general memory management strategies more so than “when does this vector self-destruct?” I find that gives me much more confidence because I’m thinking about the lifetime of my memory, not my objects.
That said, I’m not really stubborn about things here. I just changed the iterator backend to user pointers instead of index/slice combinations because I was able to save a usize and remove a bunch of math ops in the process - I feel like the program is actually much safer now because reasoning about how they move is much simpler. One thing I’ll say about Zig is that we have a heavy reliance on unsigned integers and that can create some pretty odd patterns for indexing if you’re trying to approach zero (especially with variable strides) and I wanted to resolve that in a different way.
So I’m not against indices, but I don’t see a point at this juncture to switch entirely to their model until I see some really hard evidence. I’m not convinced that if something makes sense in C++ then we should do it too. It’s also worth mentioning that a good chunk of our library uses indices instead of iterators already.
Still, I’m open to the idea and my mind can always be changed with evidence.
Thanks for the kind words, It’s been very interesting for me too, as I’m very new to programming as a whole, having the chance to work with @AndrewCodeDev what a true blessing, especially because he was able to explain a lot of the comptime stuff that was still a bit fragile for me. If you are new to Zig, I think that Fluent would be a very interesting read, simply for the fact that it uses comptime in very useful ways and honestly it shows a good variety of where and how to use comptime, which to be honest is one of the best part of Zig as a whole.
Actually I started with the comptime topic last week. I’ll take your advice and check Fluent also as part of my comptime learning chapter :). Comptime seems to be one of the star features in Zig, so it will be good to see it under different contexts. Thanks for your work!
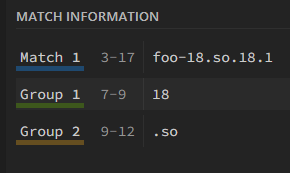
Umm how do I only iterate over the captured gourps? say my pattern is foo-(\\d+)(\\.so|\\.a).* (\ escaped) for this libfoo-18.so.18.1 i would only like to iterate over 18 and .so
also could we use it in build.zig, since it’s a standalone single file project as far i know you can expose it for build scripts by exposing using pub usingnamespace @import("fluent.zig") in the package’s build.zig.
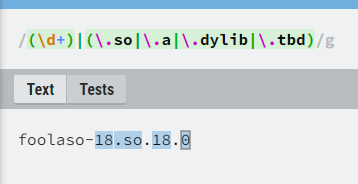
Kind of confused was using https://regex101.com/ (selected PCRE not PCRE2 from the left side) where foo-(\d+)(\.so|\.a).* pattern showed result like this:
thought it’s same for fluent but it’s different like https://regexr.com/, so regex also don’t have
“stable abi” like c++? xD guess I don’t know much bout regex after all…
Thanks for the bug report - I just pushed a change to fix it (it looks like I was missing one check for an escape after I refactored out some of the redundant regex cells).