I was also able to use some of what we talked about and I moved things over to to remove the FFI and it definitely helped! I can now hit approx 8M through python and nearly 12 million with native zig!
6 Likes
Small thing I see in your blog post:
This:
const timeV4 = Vec4{ times[0], times[1], times[2], times[3] };
and this:
const timeV4: Vec4 = times;
is semantically in the context here since times is [4]f64 and Vec = @Vector(4, f64).
Just in case you need it.
Minor terminology nitpick in your blog: what you are describing as “Structure of Arrays” is actually more akin to “Array of Structures of Arrays” (AoSoA). You are batching up tiles of (vector) lanes rather than batching tiles of individual values. More concretely:
const AoSoA = struct {
a: Vec4,
b: Vec4,
c: Vec4,
};
tile: [TILE_SIZE]AoSoA
// versus...
const SoA = struct {
a: [TILE_SIZE]Vec4,
b: [TILE_SIZE]Vec4,
c: [TILE_SIZE]Vec4
};
tile: SoA
Sorry to be pedantic. I couldn’t help myself ![]()
Until recently worked in this area. I never fully grasped the propagation parameters, but worked with talented people who understood the pieces really well.
The motivations in your blog post are on point. Fast propagation is really good. Do you think you could SIMD the look-angles for multiple lat/long/altitudes for a given satellite?
yeah, the hardest part (SIMD propagation, vectorized atan2, batch infrastructure) is already
done.
The look-angle transform itself is simpler math than SGP4, and is also is something that can be run in parellel since its based on the observer positions. Packing 4 ground positions should be a fairly easy addition and actually could be a very natural extension to this ![]()
3 Likes
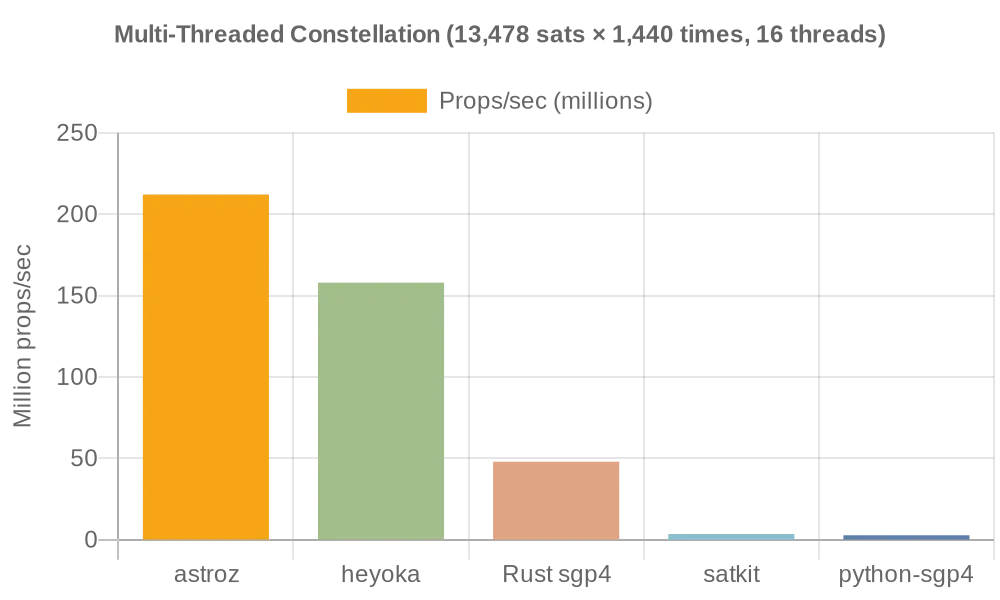
went a little more extreme than i intended to, but with multithreaded and some experimenting with memory mapping (thanks `@alignCast`), ended up on the multithreaded hitting an insane 214.2M props/sec (Ryzen 7 7840U). I think from my research, this makes it the fastest CPU SGP4 implementation ever (let me know if you find one faster!)
Can see the run in the demo: 13,478 Satellites - astroz
Also simplified the python bindings and API so you don’t have to do as much on the python side to get the best performance. You should now get the best performance everytime in most cases (i have found that if you want the absolute fastest, you will want to warmup by preloading into the cache)
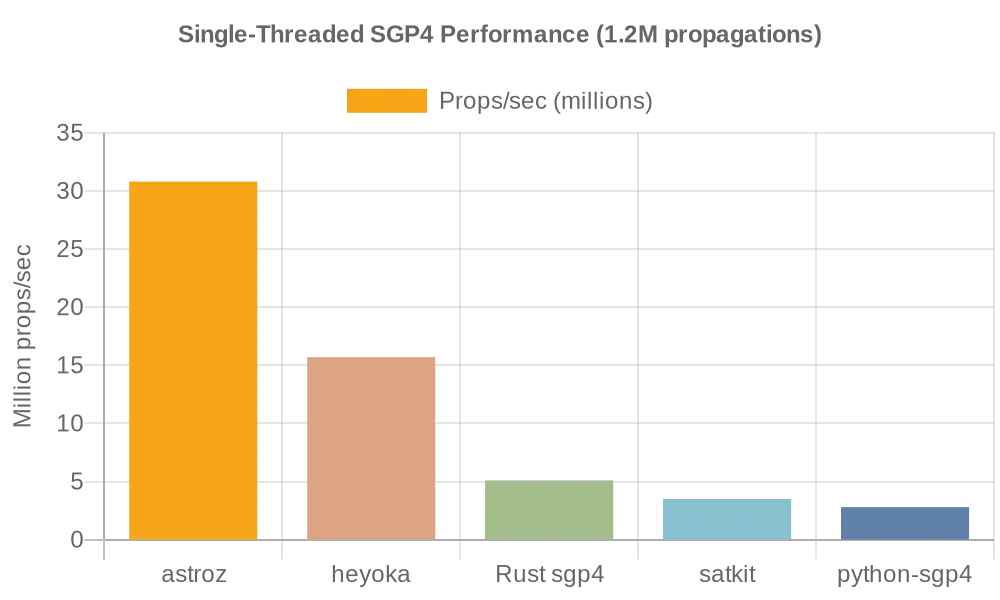
This extra tuning also helped create a kind of crazy result for single threaded as well of 30.8M props/sec. I think the math is so optimized at this point, mixed with it doesnt have to branch, it just flies through all the steps. Don’t quote me on that tho.
I think this is where my performance journey ends lol. Im not sure how much faster i realistically can make this without doing really goofy stuff like unrolling loops and handrolling asm, which i dont see myself ever doing
11 Likes